4
Developing a Small-Scale Graph Database: A Ten Step Learning Guide for Beginners
Fred Cheyunski
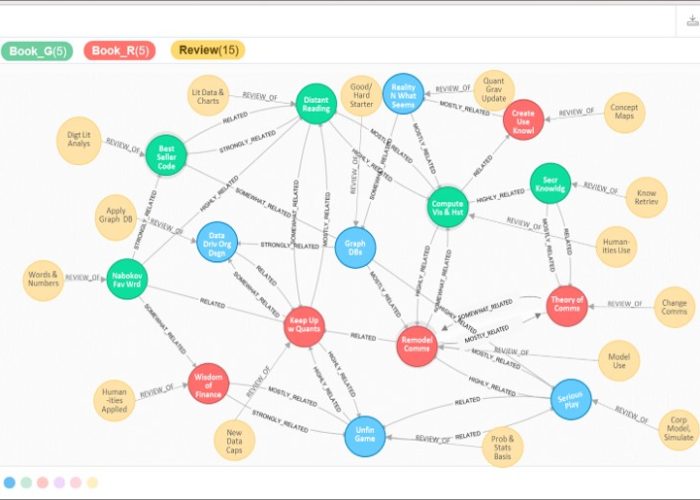
A hands-on non-programmer’s introduction to initiating and using networked information analysis for knowledge acquisition and exploration.
Read more… Developing a Small-Scale Graph Database: A Ten Step Learning Guide for Beginners