Introduction: The Challenges of Library Instruction
Library-based instruction can be a tricky thing. We usually only have one chance to give a workshop or to visit a class, so there is a pressure to get it right the first time. This is hard enough when teaching first-year students the basics of information literacy, and it presents an additional set of challenges for technology-based instruction. New technical skills are rarely acquired in 60- or 90-minute sessions. They more often require longer periods of study and build on a foundation of other technical skills that one cannot assume all participants will have (Shorish 2015; Locke 2017).
NYU Libraries offers a range of technical workshops designed to provide this technical foundation, and sessions cover topics such as quantitative and qualitative software, GIS and data visualization, research data management, and digital humanities approaches. While these workshops can be taken as one-off sessions, they are designed as part of an interwoven curriculum that introduces technical skills and concepts in an incremental way. The Collection Data with Web Scraping workshop discussed here is offered as a digital humanities course and, while there are no prerequisites and it is open to all, participants are encouraged to take the Introduction to Python and Text as Data in the Humanities workshops in advance (NYU Libraries 2019).
The workshop introduces web scraping techniques and methods using Python’s Beautiful Soup library, with a focus on developing participants’ computational thinking skills. I always emphasize that no one becomes an expert on web scraping in this 90-minute workshop, especially given that some have no previous programming experience. However, participants still learn valuable skills and concepts and through this process develop a more foundational understanding of computational logic and its affordances when applied to digital research. I call this computational thinking and it is the primary learning outcome of the workshop.
Agenda and Learning Outcomes
The workshop is divided into four sections, with the agenda as follows:
- Why use web scraping?
- What are the legal and ethical implications?
- Technical introduction and setup
- Hand-on web scraping exercises
The sections are designed to fulfill the workshop’s learning outcomes:
- Strengthen computational thinking skills
- Learn the concepts and basic approaches to web scraping
- Understand how web scraping relates to academic research
- Understand the broader legal and ethical context of web scraping
A Computational Thinking Centered Pedagogy
The primary learning objective of this workshop is to help participants strengthen their computational thinking skills. A basic working definition of computational thinking is understanding the logic of computers. It seems obvious, yet worth stating, that computers prioritize different patterns of logic than humans. There are multiple layers of complexity to understanding computational logic and then applying it in real-world research and teaching environment, and my approach is to reveal and make explicit some of these layers. For example, one of the core activities of the workshop is an in-depth look at how websites are packaged and how data, broadly defined, is structured within them using HTML and CSS. This close look at one of the building blocks of the web then allows us to identify patterns in this structured data in order to extract the useful pieces of information and build the collection. More importantly, these lessons are applicable to contexts beyond web scraping and are transferrable to our other workshops or to any activity involving data work. This gives the workshop an added value and empowers participants more confident and comfortable using technology in their research (Taylor et al. 2018).
In addition to identifying patterns in structured data, there are countless other opportunities to provide insights that give participants a deeper understanding of how technology works. For instance, when introducing the Beautiful Soup library, I describe how programming libraries are just blocks of code that allow us to write our program with 10 lines of code instead of 100. There are several web scraping programs written in other languages, but I chose Python because it has a robust developer community. That is, there are people contributing to a whole network of libraries, like Beautiful Soup, that serve to expand the functionality so that once you have extracted data from a website and are ready to analyze it, you can simply import another library, such as spaCy or the Natural Language Toolkit (NLTK) to do your next phase of work (Explosion AI 2019; NLTK Project 2019). When built into the curriculum in a thoughtful way, these parenthetical notes make it easier to learn the material at hand and also to establish a wider technical context for the work.
Why Use Web Scraping?
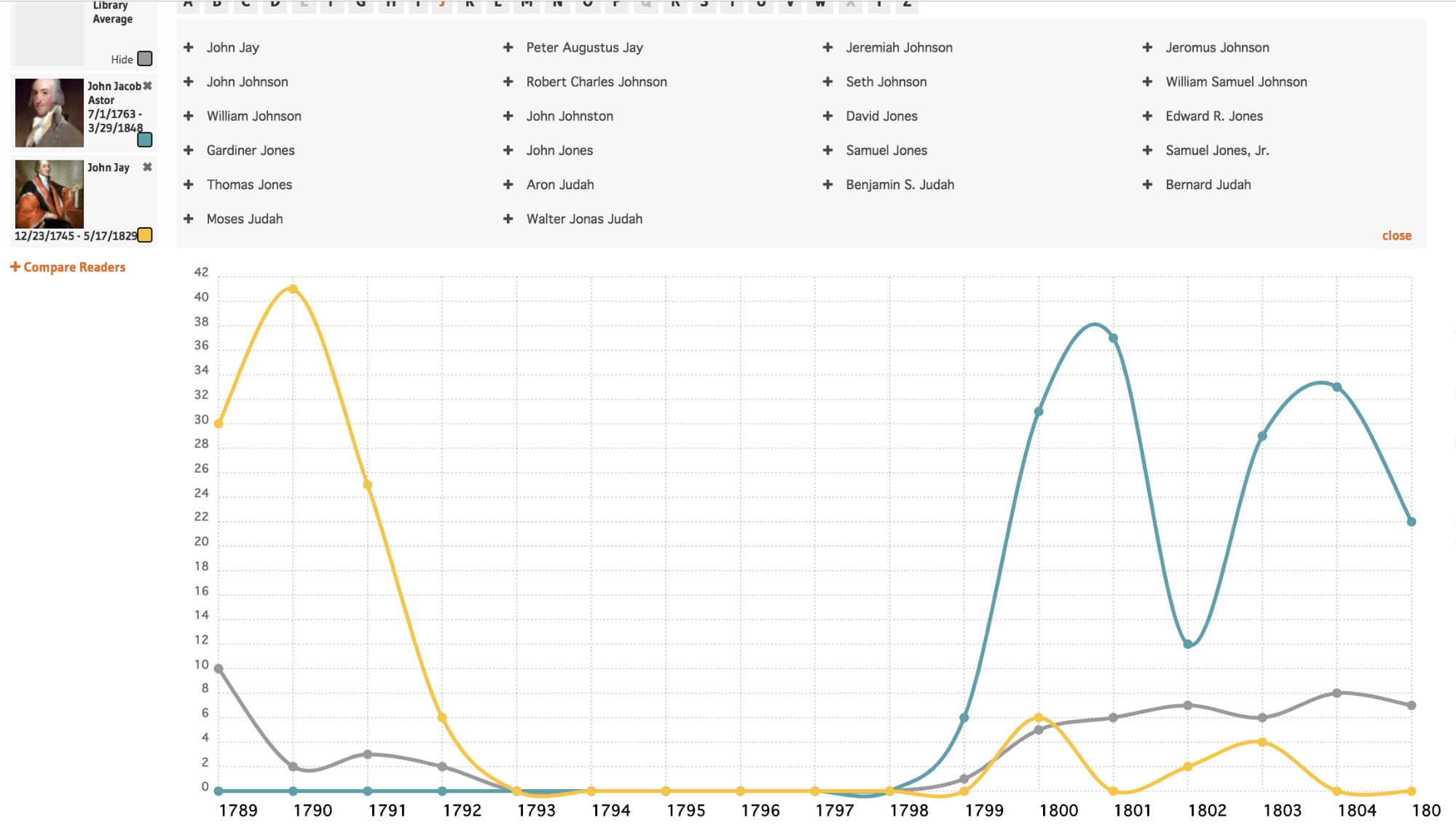
In addition to inserting computational thinking vignettes throughout the workshop, I find it helpful to begin with a discussion of why one might use web scraping. Since the workshop’s primary audience is humanists, this discussion of when web scraping is (and is not) appropriate and how it can be used in research is particularly useful. For example, as more and more primary and secondary source materials are appearing on/as websites, it is increasingly common for scholars to need to gather this material. Within libraries, archives and museums, initiatives such as Collections as Data underscore a shifting approach whereby library collections are conceptualized and provided as data (Always Already Computational 2019). Projects such as OPenn demonstrate how a library’s digitized special collections can be made accessible as machine readable and ready for large scale analysis (University of Pennsylvania Libraries 2019). An additional example, the New York Society Library’s City Readers project, presents the Library’s early circulation records as data, allowing users to, for example, compare whether John Jay or John Jacob Astor read more books in a given year (The New York Society Library 2019). Such examples help participants envision how they could use web scraping in their work.
Another core concept of the workshop is that web scraping will become one of many skills in participant’s “digital toolbox,” and can connect with other technical skills used in the research lifecycle. For example, data gathered from web scraping is often messy and often needs additional scrubbing in a program like OpenRefine (MetaWeb Technologies, Inc. 2019). Or, web scraping might be just one step in text analysis project, and you might want to use a named entity recognition (NER) package to next extract names of people or places from the scraped dataset.
What are the Legal and Ethical Implications?
Next is a conversation about the legal and ethical implications of web scraping. The key lesson here is that just because you can scrape a website, it doesn’t mean you should. It is important to first check a site’s terms of use policy to understand whether there are rate limitations or if scraping is outright prohibited. Collecting certain types of online data on human subjects (e.g. some types of social media data) will require IRB approval. After collecting data, scholars will also need to consider how will the data be stored or archived and whether this has the potential to put others at risk. This is a particularly pertinent concern for materials dealing with controversial subject matters or underrepresented groups. The Documenting the Now project has many great resources to help navigate these often complex issues (Documenting the Now Project 2019).
In terms of research best practices, it also takes some data literacy basics to evaluate your target source. There is a lot of garbage online, and how so do you know the data is what it claims to be? Is it representative and what biases does it contain? And research projects using digital sources or methods are no different from more traditional approaches in that getting the data or producing a visualization of it is often not the end of a project. In most cases, the data must then be analyzed in a theoretical framework of the scholar’s discipline in order to form a scholarly argument. The earlier cited example of the New York Society Library illustrates this well – the circulation record visualization shown above is an interesting anecdote but the image is a relatively simple data visualization and does not actually tell us anything meaningful about, say, the American Revolution or eighteenth-century reading patterns.
Using Beautiful Soup
While asking participants to bring their own laptop and set them up with their own Python environment provides rich opportunities for moments of computational thinking, it is time intensive, demanding on the instructor, and requires a longer workshop. A simpler approach is to use an already exiting environment such as JupyterHub, PythonAnywhere, or a computer lab with Jupyter Notebook installed (Project Jupyter team 2019; PythonAnywhere LLP 2019; Project Jupyter 2019).
Beautiful Soup is a Python library for extracting textual data from web pages (Richardson 2019). This data could be dates, addresses, news stories, or other such information. Beautiful Soup allows you target specific data within a page, extract the data, and remove the HTML markup surrounding it. This is where computational thinking skills are needed. Webpages are intended to be machine readable via HTML. The goal is to write a program, in machine readable form, that extracts this data in a more human readable form. This requires that we “see” as our computers “see” in order to understand that if, for example, we want the text of an article, that we need to write a program that extracts the data between the paragraph tags.
<p></p>Once we understand the underlying rules for how pages are displayed – i.e. using HTML and CSS – we can start to see the patterns in how content creators decide to present different types of information on pages. And that is the computational thinking logic behind web scraping: identifying these patterns so that you can efficiently extract the data you need.
Computational Thinking in Action
The examples used in the workshop are available online (Coble 2019), and working through the first example – collecting the titles from the Craigslist page for writing, editing, and translation – will illustrate some of these concepts. While the research value of this data is rather limited, it is a straightforward example to introduce basic techniques that are built upon in subsequent examples.
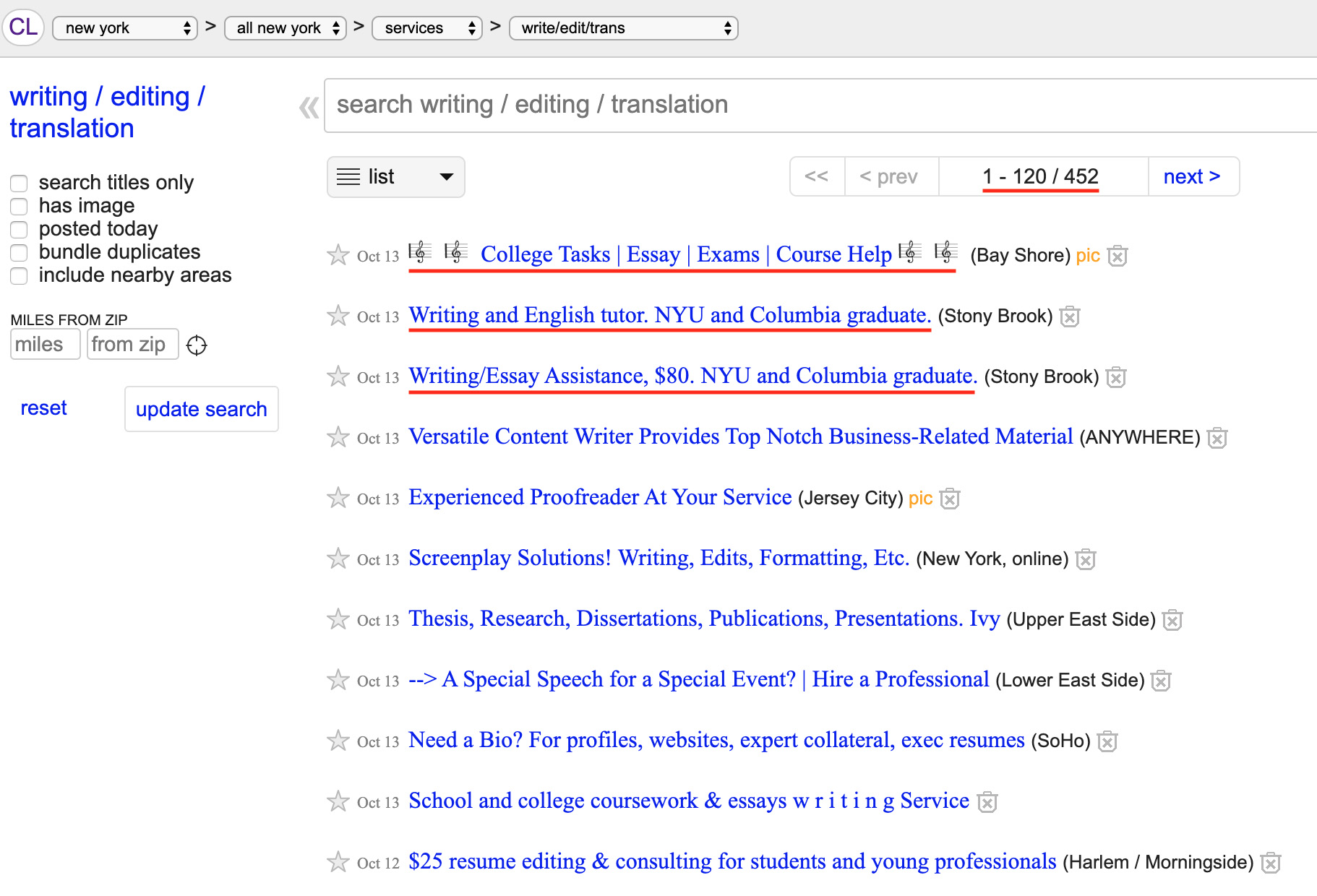
The first step is to use the browser’s View Source feature to look at the page’s HTML code. Not only do we get a quick glimpse into how the data is structured, we can also begin to identify the parts of the code that uniquely mark the title of these posts.

For example, here is the source code for the first post on our page:
<a href="https://newyork.craigslist.org/mnh/wet/d/brightwaters-college-tasks-essay-exams/6998844623.html" data-id="6998844623" class="result-title hdrlnk">🎼 🎼 College Tasks | Essay | Exams | Course Help 🎼 🎼</a>Let’s start by breaking this into parts:
a href="https://newyork.craigslist.org/mnh/wet/d/brightwaters-college-tasks-essay-exams/6998844623.html"The above part is the link to the full post. We don’t want this because it’s not the title.
data-id="6998844623"This looks better, but data-id appears to be a unique identifier for a specific post. If we write a program to search for this, it will only return one title. This won’t work because we want all titles of posts on our page.
class="result-title hdrlnk"This looks much better. But there are actually two class tags here, class=”result-title” and class=”hdrlnk” (condensed and separated by a space), so which one is best? We can do a quick check by searching on the View Source page – using Cmd+F or Ctrl+F – for “result-title.” There are 120 posts displaying on my page, and the search for “result-title” returns 120 results. Bingo!
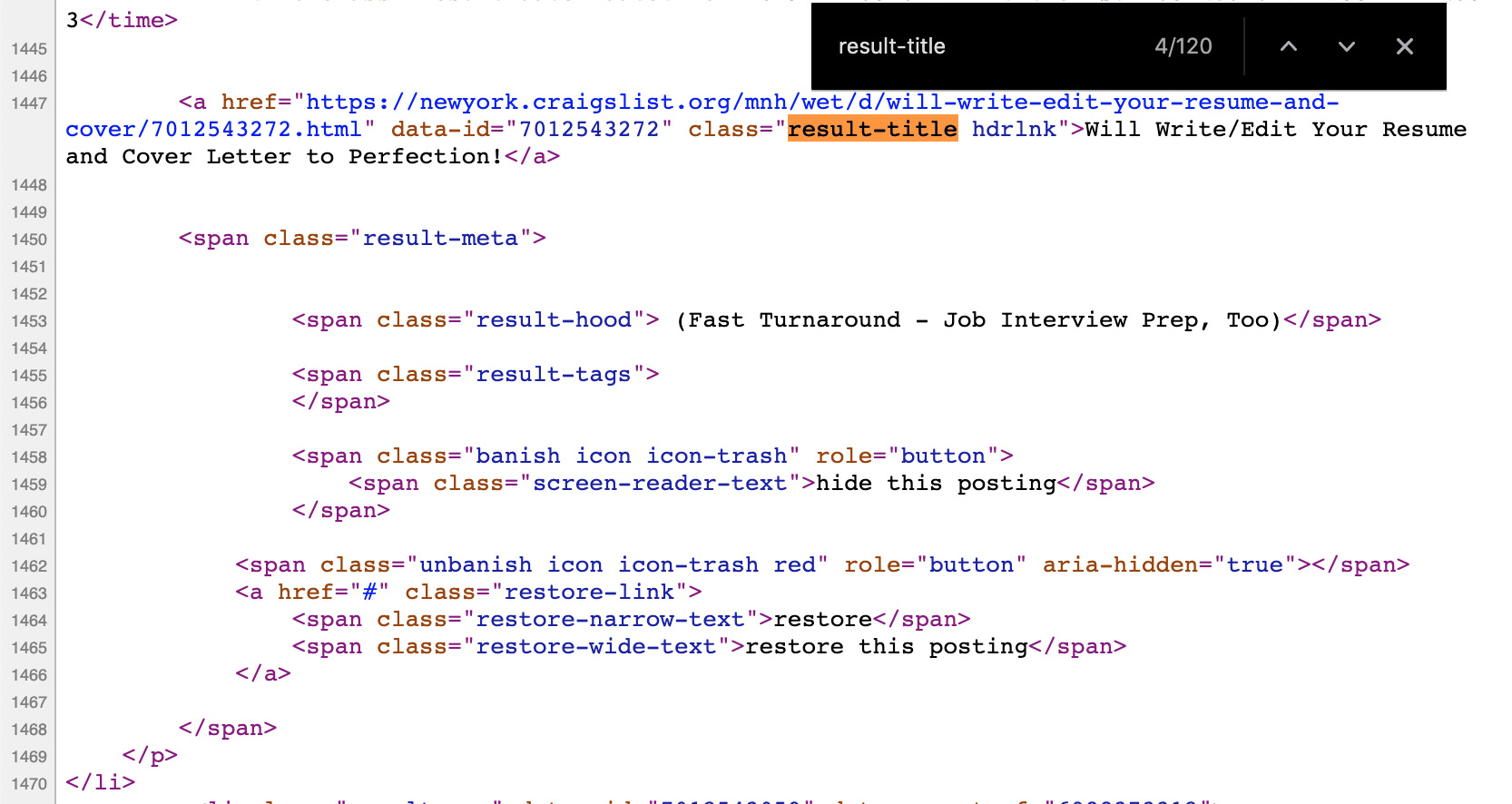
We can repeat this process for “hdrlnk,” which, in this case, also returns 120 results. So we can comfortably use either “result-title” or “hdrlnk” for our program. To be safe, I would also do a quick manual check of other links on the page – both links for posts and for other links (My Account, Save Search, etc) to confirm that “result-title” and “hdrlnk” is the unique string that will return the post’s title and only the post’s title.
And this is the computational thinking the workshop helps to build. By understanding how web pages use HTML and CSS to structure their contents, we are able to isolate patterns unique to our target data and to use these patterns to extract the target data. Once we have these pieces in place, we can write a program that looks like this:
# import the urllib library to get the HTML
import urllib.request
# import the Beautiful Soup library to parse the HTML
from bs4 import BeautifulSoup
# define a variable with our web page
start_url = 'https://newyork.craigslist.org/search/bar'
# ask urllib to get the HTML from our web page
html = urllib.request.urlopen(start_url).read()
# ask Beautiful Soup to parse the web page as HTML
soup = BeautifulSoup(html, 'html.parser')
# ask Beautiful Soup to extract the titles
titles = soup.select('.hdrlnk')
# for loop to print each title
for title in titles:
print (title.text)And get something back that looks like this:
🎼 🎼 College Tasks | Essay | Exams | Course Help 🎼 🎼
Writing and English tutor. NYU and Columbia graduate.
Writing/Essay Assistance, $80. NYU and Columbia graduate.
Versatile Content Writer Provides Top Notch Business-Related Material
Experienced Proofreader At Your Service
Screenplay Solutions! Writing, Edits, Formatting, Etc.
Thesis, Research, Dissertations, Publications, Presentations. Ivy
--> A Special Speech for a Special Event? | Hire a Professional
Need a Bio? For profiles, websites, expert collateral, exec resumes
School and college coursework & essays w r i t i n g Service
$25 resume editing & consulting for students and young professionals
Don't Just Talk! Communicate - Medical School Intervew
Grad/law/MBA/med school personal statements due?
FOR HIRE: AWARD-WINNING, IVY-EDUCATED EDITOR/SCRIPT CONSULTANT
Pay me write your essay, edit your work, take an classes fully online
FAST Affordable Dissertation and Academic EDITING-NonNative English OK
Versatile Content Writer Provides Top Notch Business-Related Material
Winning Resume, Cover Letter and LinkedIn Package For $30
French writer and translator
Writers for FrontPage.nyc
Academic Intervention & Paper WritingConclusion
Bringing computational thinking concepts to the forefront of the workshops has been successful and resulted in more engaging sessions. Participant feedback has indicated that having a greater contextual understanding of web scraping and learning about its underlying principles has helped them better understand its potential applications and to feel more confident in doing their work. Given the nature of library-offered technical workshops, focusing on a computational thinking–centered pedagogy has been successful in helping participants to meet their specific need to pick up a new skill as well as to meet a less often stated need to understand how and why a particular tool or approach is situated within larger research and technology ecosystems.
