
How I learned how to Stop Worrying and Pickle Websites: The Art of Fermenting the Web with Archive-It and Webrecorder
Stephen Klein, The Graduate Center, CUNY
An analysis of Archive-It and a rudimentary attempt to transcend its limitations using Webrecoder to preserve digital scholarship.
As modes of communication increasingly migrate from print to digital formats, digital preservation is an imperative within the academy to ensure the continual creation of knowledge and scholarly conversation. However, unlike print media, for which time-tested architecture for protecting and accessing content already exists, in the form of appropriate shelving, knowledge of best climatic conditions and online catalogs, sophisticated solutions for preserving and accessing complex digital objects are still very much in their infancy. Websites, for example, pose a particularly acute challenge; most solutions that preserve websites are not sophisticated enough to capture a website’s full (interactive) functionality, and original content might be lost.
As the Digital Services Librarian at the CUNY Graduate Center, the person responsible for preserving born-digital components of theses and dissertations, I became acutely aware of students’ increasing inclusion of born-digital projects, particularly websites, as elements within dissertation and thesis deposits. Capturing and preserving these digital elements is important in order for the scholarly conversation to continue.
After exploring an array of options (such as Wget, HTTrack or installing a local version of Heritrix) available for web archiving, at the Graduate Center we invested in an Archive-It subscription for several reasons. First, subscribing would relieve us of hosting a server and correctly configuring Heritrix, the default standard application that crawls sites and creates WARCs (web archive file). Second, Archive-It hosts the preserved copies (WARC files) of these sites, meaning we would not have to be concerned with backup of the WARCs. In addition, Archive-It allows for easy access to the WARC files via the Wayback Machine.
Over the course of using the Archive-It service, we came to better understand some of the limitations of Heritrix (again, the crawler that Archive-It uses). The biggest limitations are Heritrix’s inability to execute JavaScript (it is not a client/browser, so it only reads the code, but does not execute it) as well Heritrix’s inability to present dynamic data that is stored in a website’s database. This poses issues for archiving digital work that includes maps, timelines, SoundCloud files and other forms of embedded media and database driven content.
For example, Archive-It was not able to capture many important elements in Gregory Donovan’s My Digital Footprint project.
Here is the original with a timeline:
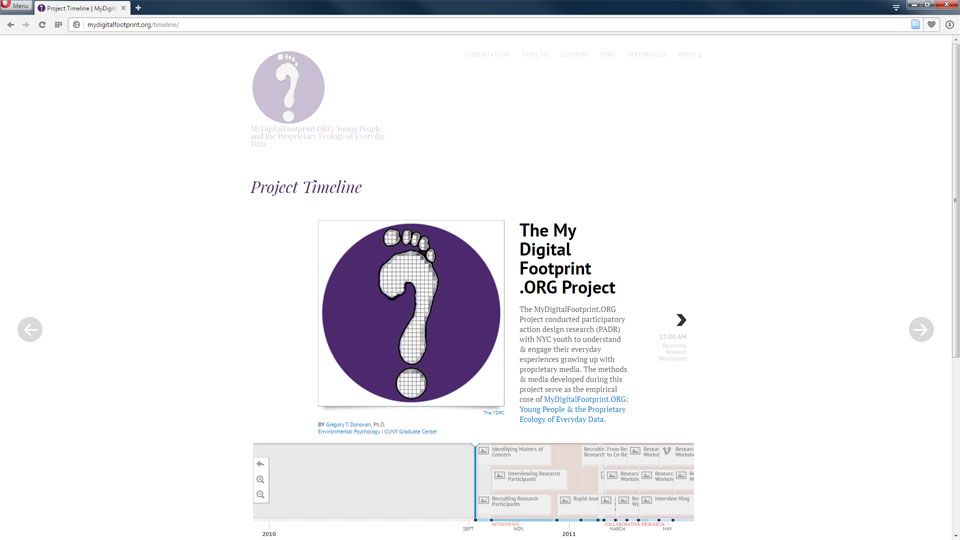
Original un-archived site with interactive timeline.
The archived version does not show the timeline:

Archived site with missing timeline.
The original also contains a SoundCloud embed:
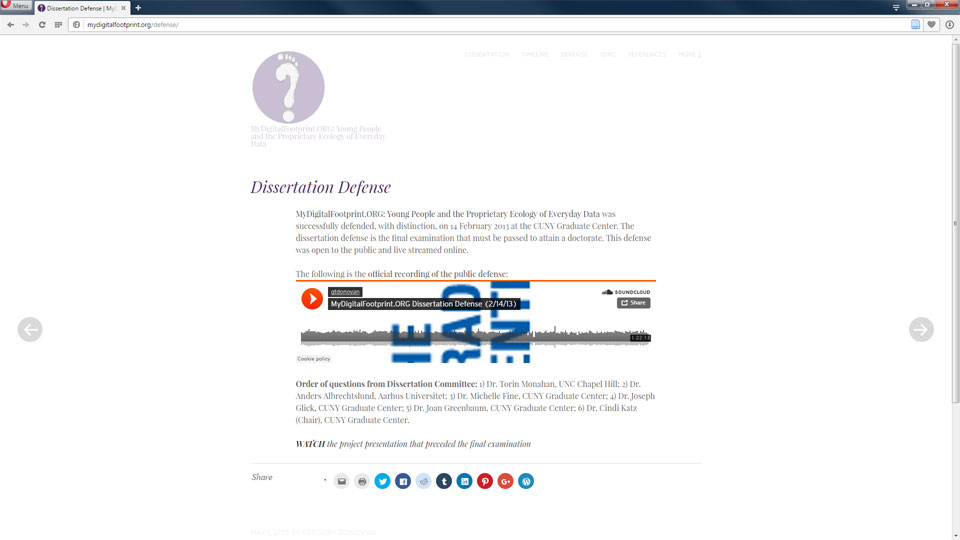
Original site with embedded SoundCloud recording.
But the archived version does not show the SoundCloud embed:

Archived site with missing SoundCloud recording.
Another example of an unsuccessful crawl is Heather Spence’s ‘Dolphin Bioacoustics Policy Online Database Project.’
The ability to build complex searches is central to her project. For example, the following query (Sort by <Author> and Order by <Desc>):
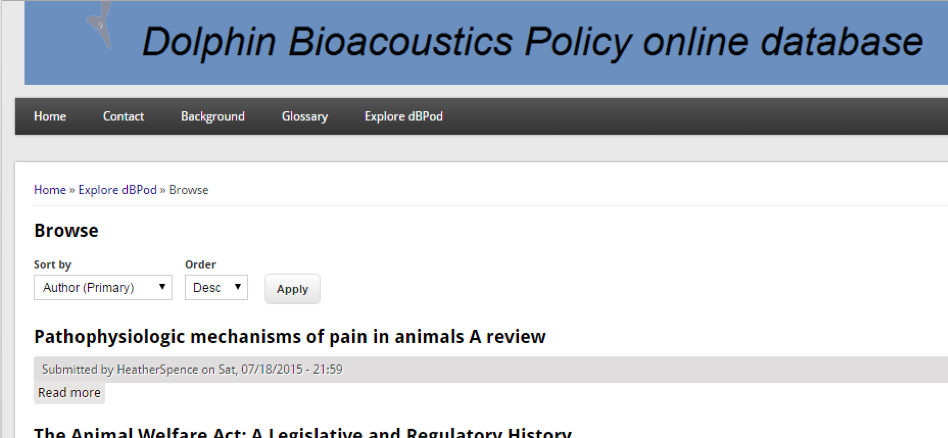
Using the query builder in the original site.
Returns the following in the live version of the site:
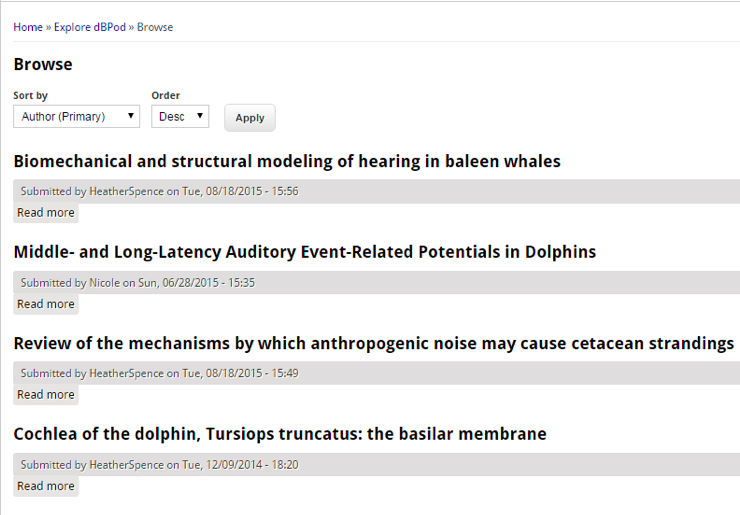
Results in this list of items.
Allowing users to see a full record by clicking on a title:
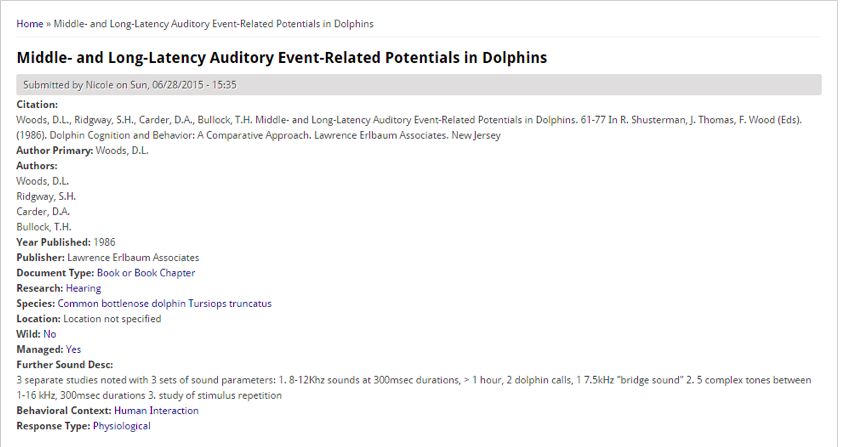
Click on a bold title results in a full record.
However, in the archived version, clicking on a title reveals that the search results were not actually captured by Archive-It’s crawler and the user encounters a ‘Not in Archive’ message:
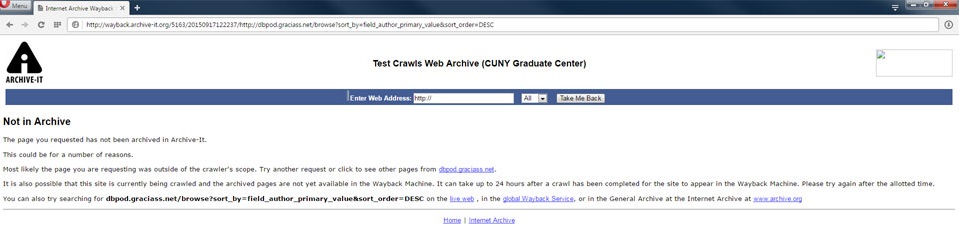
Because of the desired web page is dynamically generated from a database query it is impossible for it to be captured by Archive-It, resulting in ‘Not in Archive’ page.
Many students are working on mapping projects. For example for the Graduate Center Digital Praxis course in 2015, a group of students put together this interactive mapping site:

Interactive Map on live site.
All interactivity is lost in the archived version of the map:
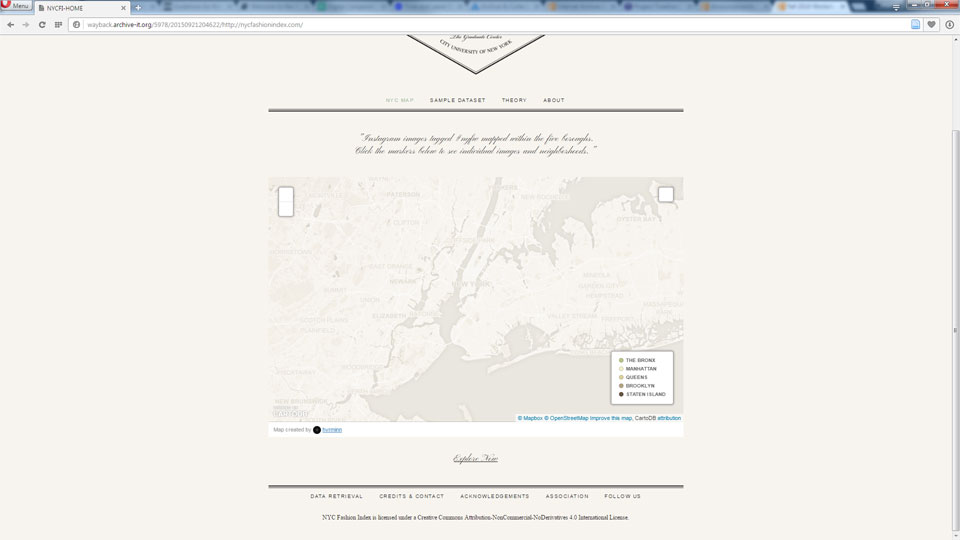
Map Interactivity interactivity is lost in the archived version of the site.
The inability to create a perfect archival copy was the predominate reason motivating us to look for other tools that could supplant or supplement the Graduate Center’s Archive-It subscription. Although students have yet to send me any WARC files generated from the tool, the CUNY Graduate Center Library has decided to supplement our Archive-It captures and playback with Webrecorder WARC files generated by students themselves. Because the students are experts in their own work, the process of self-archiving seems logical because they best know how to navigate the most relevant links and interact within their site to capture content.
Webrecorder is a small-scale, open-source tool built by Rhizome that runs in a browser, which allows direct recording of the users’ in-browser experience, including dynamic content such as audio/video content and search results. Because users approach a web project from an in-browser experience, Webrecorder WARCs are more like documentation of a project rather than a full archival record. With Webrecorder’s sister project, oldweb.today, which serves as a search engine and emulation platform for WARCs, the folks at Rhizome hope to help make accessible and preserve the web. Recording users’ interactions with websites means that Webrecorder is able to record the output of JavaScript functions that run as the user’s interactions on a website execute the background JavaScript.
The interface is very simple and easy to use. Although Webrecorder is offered for local installation within a docker container, for our pilot project the Graduate Center has elected to tell students to use the Webrecorder site itself, which currently offers free creation of individual accounts with up to 10 collections and storage up to 5GB. It is also possible to record sites anonymously, without creating an account.
Using Webrecorder:
Note: The Webrecorder interface is under rapid development and although the following illustrated the ‘essence’ of the tool, it may not completely reflect its current manifestation.
Note: Anonymous users can create WARC files, but registered users have the advantages of 5GB of archiving storage space.
Registered Users:
After registering, logged on users create a collection with the <New Collection> button.

After login, registered users are prompted to create a new collection.
The <Create a New Collection> dialog appears. Enter the collection name in the <Collection Name> field, decide if you want to make your WARC visible to the public and then click on the <Create> button.
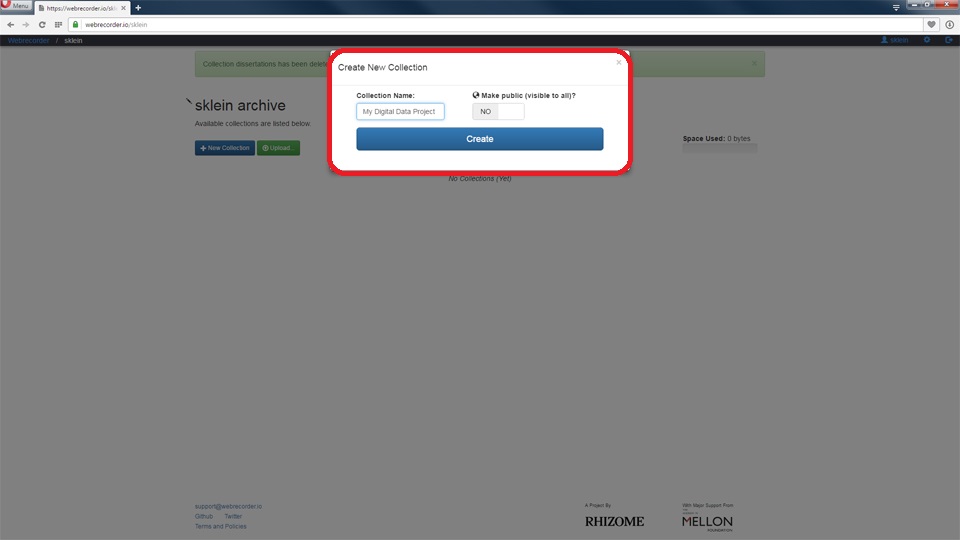
The Create a New Collection Dialog.
Users are then returned to their Collection Page. On the Collection Page, users can simply click on the <New Recording> button.
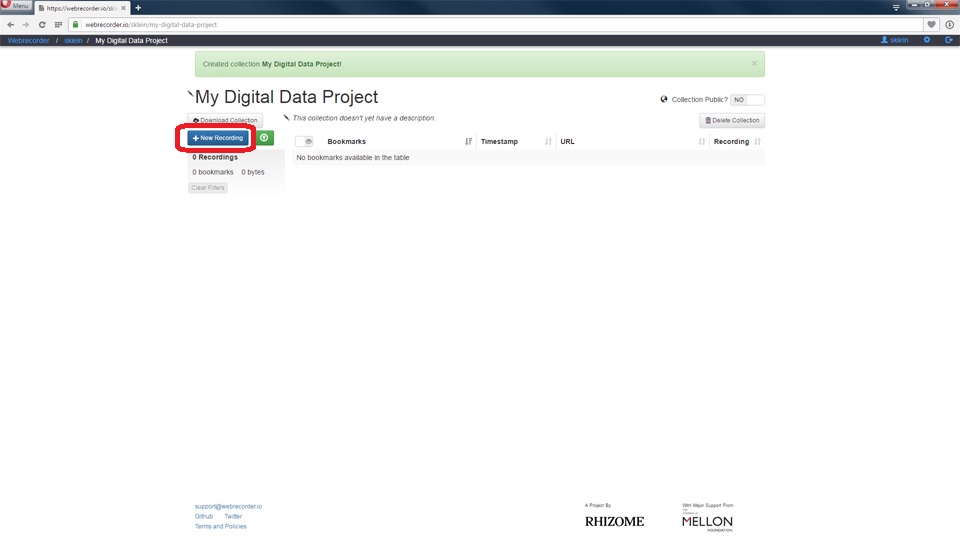
The Create the New Recording button to begin the recording process.
Clicking on the <New Recording> button allows users the opportunity to enter the URL of the Website they want to record and cue to the desired location.
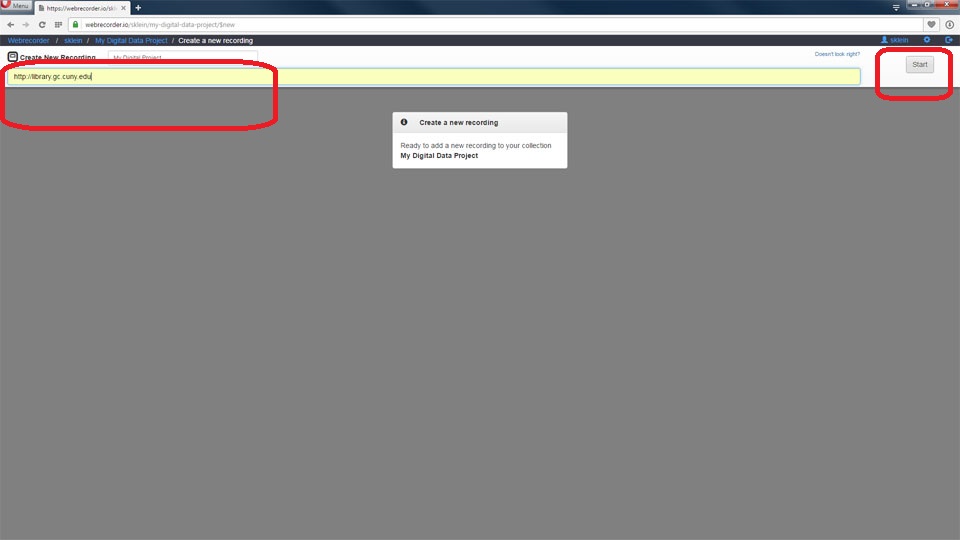
Users are prompted to enter the URL of the site that the want to record and then click the button.
After clicking the start button, the desired webpage will load. Click through the desired interactive elements within the page and all pages that you want to capture. The Webrecorder page header contains useful information, for example it will show that a recording is occurring, the current size of the recording and the number of pages (bookmarks) captured. When done click on the <Finish> button.

The Header of the Webrecorder showing userful information.
After clicking on the <Finish> button, the user is returned to the Collection Page allowing the user to view the list of all pages captured, download the collection (WARC file), delete the collection or make the collection public.

The Collection Page after recording providing the options of downloading, deleting and or making the collection public.
Anonymous Users:
To capture a website, the user simply enters the URL for the site and clicks <Record>. If you intend to use for more than one project, enter a recording name the <New Recording Name> field.
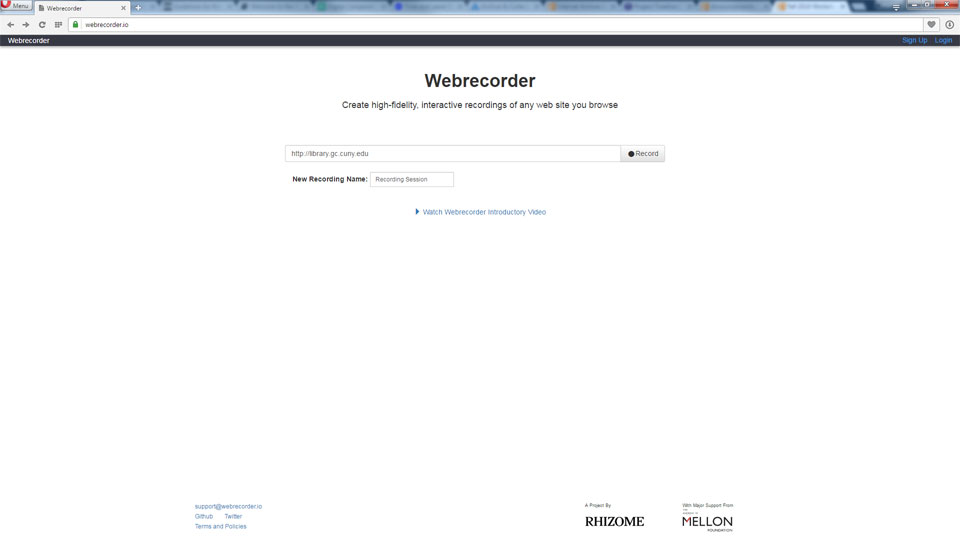
The user merely needs to enter a URL and click to load and record a desired website.
The Rhizome folks provide a concise video tutorial on youtube on basic Webrecorder usage.
Users can test their WARC by downloading the Web Archive Player on github.
Evaluation
In terms of user experience, I have found Webrecorder very easy to teach and use. Assessed from many one on one research consultations, students appear to quickly learn how to record their digital projects. The library requires students who deposit theses or dissertations with born digital components to send the Graduate Center Library the file that we then upload to our institutional repository. We more fully explain the entire process here.
From both a scholarly and administrative point of view, more complete preservation of content is clearly a big advantage. We are pleased with the increased proportion of dynamic content that Webrecorder captures in comparison with our experience of Archive-It. However, this tool is in development and at present offers limited functionality. For example, it currently does not offer automation for any of the process, so it may not be completely scalable for gigantic data orientated projects; it is necessary for the user to manually load every page they want to capture. It is a big advantage that Webrecoder is free, but the hosting costs for local storage and long-term preservation of the WARC files created with this method require further investigation.
Conclusion
Evaluating the benefits and drawbacks of these two tools for web archiving, we found that there are tradeoffs to be had in either method. At present, requiring students to use Webrecorder is a great supplemental approach to our Archive-It subscription, primarily because Webrecorder is more effective for capturing dynamic content than Archive-It. For now, asking students to self-archive their own work is manageable, given the small scale of student projects, although the manual process of capturing web content from a large (data based) project can be time consuming and may prove unsustainable for larger projects. It has been encouraging to begin making progress toward capturing the websites which are fast becoming an important part of scholarly conversations.
Appendix: Slideshow Presentation
Acknowledgement
The author thanks the Rhizome folks, especially Morgan McKeehan (a National Digital Steward), who provided insight and some guidance on the best way to understand, teach and present the potential of Webrecorder.
Stephen I. Klein, the Digital Services Librarian at the Mina Rees CUNY Graduate School Library, spends much of his work-life behind the scenes insuring that the pulse of the GC’s library systems continue to work seamlessly for library users. He also spends time ‘freaking-out’ about the crisis of how our cultural heritage is quickly disappearing, because of the acceleration of modern ephemera with the advent of the web as one of the central forums for popular conversation and academic scholarship.
'How I learned how to Stop Worrying and Pickle Websites: The Art of Fermenting the Web with Archive-It and Webrecorder' has 4 comments
September 5, 2022 @ 4:09 pm ditch22
hello, thank you for this post. May i use some of the information you provided here for my project? i will provide you with credits .
July 8, 2022 @ 5:35 am john
Hello, thank you for this information. I have used some of the information as reference on my blog.
January 24, 2020 @ 8:06 am Vicky
hello, thank you for this post. May i use some of the information you provided here for my project? i will provide you with credits
September 21, 2016 @ 1:47 pm How I learned how to Stop Worrying and Pickle Websites: The Art of Fermenting the Web with Archive-It and Webrecorder
[…] For example of how Archive-It was not able to capture many important elements in Gregory Donovan’s My Digital Footprint project, view the original post on the Journal of Interactive Technology and Pedagogy by clicking, here. […]