In the humanities, we train students to interpret their material within a larger context. Facts exist to be contextualized, biases uncovered, problems revealed. Students in many corners of the humanities are rarely confronted with something termed data, which they imagine as dry and quantitative and unyielding. Art history in particular is still a discipline of printed books and, especially, of material objects. Of course data do exist in our field, adhering to objects as physical information or tagged contents, or to the objects’ makers, as in the University of Amsterdam’s monumental ECARTICO project (Manovich 2015; Bok et al. n.d.). But introducing students to data is normally much less central to our work than persuading them to engage in close examination of the visual, and to use libraries to gather information.
Modern engineering is distinguished by production of massive data, most of which can be accessed from all over the world. Engineering students often take computer science and statistics classes, in addition to a curriculum in their chosen field, as a way of acquiring the expertise to deal with modern data. In the engineering realm, quantitative data are central and the context from which data arises is usually not discussed. As a result, engineering educators have devised pedagogy to motivate students to contextualize findings. One of the primary ways that engineering pedagogy has changed in the past twenty years to meet this challenge is the introduction of experiential and project-based learning (Crawley et al. 2007; Savage, Chen, and Vanasupa 2008). Both of these approaches are designed to couple the development of technical skills with increasing contextual awareness and cultural literacy. In this paper, we unpack key assumptions at the heart of the current state of pedagogy in both engineering and digital humanities by posing two questions:
- Does digital training in the humanities alone motivate students to consider an outward focus for their contextual learning, and
- Does project-based learning in engineering motivate students sufficiently to dig below the exploration of data and production of visualizations, and into context.
We implicitly challenge the notion that teaching digital humanities and the construction and meaning of “data” is enough to create a digital scholar. In engineering, we challenge the notion that a shift to project-based instruction is sufficient to motivate student learning beyond digital skills and computational methods.
To conduct this study, we consider how one data set functioned pedagogically in a humanities course taught within an art history department, and how the same data and core assignment was used in parallel in a data science course taught in engineering. In both cases, the process of working with data was meant to unsettle the ways in which students had normally been asked to work in their discipline. “Data” was framed as both a subject of analysis and a pedagogical tool to make students question their habits of thought, further empowering them to ask questions they had never thought to ask before. In both cases, students had to move back and forth between interpretability and quantification, recognizing the limitations and opportunities of approaching their data as (historical) material, and organizing their historical material as data.
The Humanities Class
The course “Humanists on the Move” introduced liberal arts undergraduates to data gathering and structuring as well as visualization and analysis. The goal of the class was to make students engage with the most fundamental humanities source material—primary written historical documents—as well as with data: the former should make the analysis of the latter meaningful. In fact, by the end of the semester, the class would not merely have learned about the early sixteenth century, about individual humanist figures, and about data and their analysis, but as a group the students would have produced new knowledge about this historical period, things that could not have been found in any published source.
Each student took on a single humanist figure for the semester. The characters ranged from Martin Luther to Isabella d’Este, Erasmus to Copernicus, Henry VIII to Cellini and Leonardo da Vinci. Students worked in groups according to the type of figure they were studying: Rulers, Artists, Scientists, and Thinkers. Every week the class read and discussed a primary source text, “met” its author, and investigated the historical context within which that figure had lived and ruled, painted, or written. Students learned enough about their own figure’s life to provide both a short written introduction and a longer oral presentation about them to the class. Having attained familiarity with their figures, other students’ figures, and a sense of the period based on contemporary writings, students then moved on to consider how the humanists’ historical roles were impacted by mobility and network-building—and, further, how other variables (gender, profession, national origin) factored into these complexities. This process required original research, and would necessitate collecting, structuring, cleaning, visualizing and analyzing data.
Using biographical sources, particularly actual printed books (which many in the class had never thought to consult before), students first gathered information on the travels of their figure: locations visited, and dates of travel. They geocoded each location so that it could be mapped, and they structured their material as data, each creating a three-sheet Excel spreadsheet. The members of each group then combined their data into a single spreadsheet, so that all Rulers, or all Artists, would eventually be visualized and analyzed together.
The class was initially held at UMD’s Collaboratory, where Collaboratory staff introduced students to OpenRefine, an open source platform created in Google Labs (originally as GoogleRefine) to clean and parse data using a simple set of tools (Muñoz 2013a; 2013b; 2014). This introduction covered installation and basic use. Each time it is opened, OpenRefine creates a server instance on the host computer, which is interfaced via a web browser. Users can open a local dataset (the default choice), as well as live data accessed via a URL (e.g., that of the City Permit Office of Toronto, Canada which is the basis for the tutorials on using Open Refine found in the Documentation section at openrefine.org).
Using a dataset contained within an Excel spreadsheet, “Sample Messy Humanist Data” provided by Professor Elizabeth Honig, Christian Cloke and Quint Gregory demonstrated the use of basic tools within OpenRefine, such as Common Transforms, Faceting, and Clustering, which allow the user quickly to reconcile data values that may be similar though not the same (such as capitalized/not-capitalized entries; misspellings; those with a space after or before a string). Through such operations, which require one to think carefully about how the data are structured, the user develops a deeper awareness of the dataset and confidence in its soundness and consistency. In addition, students were shown how different columns of data could be joined or split, depending on the desired outcome, to make new data expressions. The resulting “cleaned” dataset could be exported to a data table in any number of preferred formats (CSV/TSV, Excel, JSON, etc.).
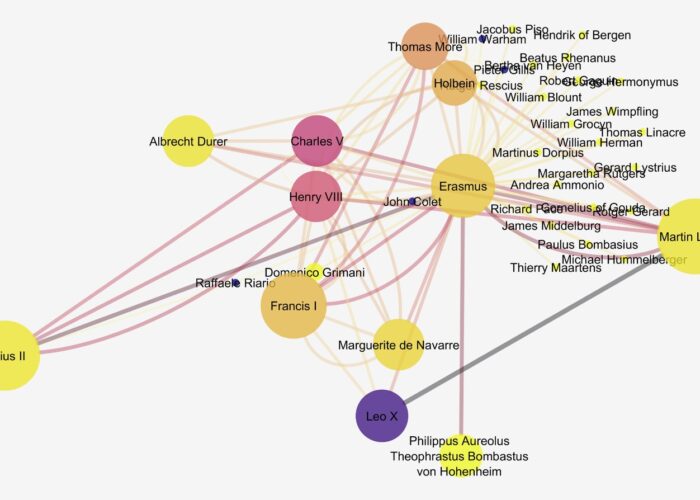
To visualize their travel data, students were trained to use the Stanford-based platform Palladio (Humanities + Design n.d.). Palladio is an open source tool that was originally conceived of to visualize data from the “Mapping the Republic of Letters” project, which had collected material on scholarly networks in early modern Western Europe. Its main capabilities are therefore the visualization of networks and the creation of maps. Designed to be usable by humanists, Palladio does still necessitate correctly structured data, and students explored how that structuring impacted the generation of maps in Palladio’s system. Within its map function, Palladio also allows the visualization of chronological data linked to travels as both a timeline and timespans, so that the user can see the locations mapped (with locations sized according to criteria such as number of times visited) and the years in which travels occurred (Figure 1). Palladio also allows for “faceting,” i.e. dividing and recategorizing elements of data so that it can be examined in another dimension. For example, faceting enabled students to study over what distances female humanists were able to travel, or what cities attracted the most scientists vs. the most theologians, or which figures might have been together in Rome during a given year.

Based on the maps and faceting, and on their research on individual figures whose travels were now visualized together, the class was able to explore what life events, ambitions, and exigencies led to travel in the Renaissance, and how travel mattered differently to figures with different professions.
The Data Set
The data set shared between humanists and engineers was created in the next phase of “Humanists on the Move,” which concerned humanist networks. Historical networks have been thoroughly studied and, more recently, elegantly visualized. The vast and remarkable website The Six Degrees of Francis Bacon, hosted by the Carnegie Mellon University Libraries, is a model of what a collaborative project using humanities data can accomplish (Lincoln 2016; Moretti 2011). Nevertheless, network material as we imagined it would be considerably less clear-cut as data than travel had been. A person is or isn’t in a given location at a given time, but a connection—in network terms, an edge—is harder to define. There are obvious connections such as family, colleagues, allies, collaborators. But when a figure read a book by another humanist, did that make them connected? And if so, how deeply connected had they become? How would the importance of that connection compare to, say, attending a performance in which another figure had acted, being present at a diplomatic meeting but not as a main player, writing a letter but (as far as we know) never receiving a reply to it? Historical resources are often fragmentary, and the class tangled with how to account for that as they assembled data. These were issues that most undergraduates had never confronted as they studied history, but now, history’s lacunae were of immediate relevance to their work.
In structuring their data, students were asked first to come up with a limited set of labels that would describe relationships. These might include patronage, respect, influence, friendship, antagonism. Often they encountered an example that none of their labels seemed to fit, but which was not sufficiently different, or representative, to warrant a new label. They learned how to compromise. Next, the students had to agree on criteria by which those edges could be weighted on a scale of one to three.
Another way of thinking about this exercise entails recognizing that it involved phases of translation, from humanist ways of thinking about material into quantifiable terms and then back again (Handelman 2015; Bradley 2018). Describing relationships, even determining what makes a relationship and why it matters, is a perfect example of humanistic work. Art historians love to talk about influence, patronage, and collaboration; this is all fundamental to how we write our histories. We could all probably say who was an important patron or a minor influence. But the students were asked to take information they had gathered and make it numerically regular, working against the humanist instinct to value irregularity and to see each instance of a given relationship, whether patronage or correspondence, as essentially a unique event with its own characteristics that are not simple to equate with those of a comparable event (Rawson and Muñoz 2016). Now every relationship had to be described using a fixed term from a limited list; every edge had to have a weight, from one to three. Long discussions were involved, although the COVID pandemic was widespread and we were meeting via Zoom.
The class gathered nearly 700 connections representing the ways in which over 450 different persons were connected to our core of twenty humanist figures (Figure 2). All of the groups combined their data into one large class spreadsheet. Every person (node) was described by a profession, every relationship (edge) had a label, sometimes several, and a numerical weight. This was the data set that we passed along to the engineers.

Engineers, Data, and a Humanities Data Set
The course “Data in the Built Environment” is designed to teach data science skills to graduate engineering students. One of its main aims is to motivate students to dig deeper into context via project-based learning concepts (Hicks and Irizarry 2018). To do this, students are given a new dataset each week with which to practice a newly introduced data science technique. Students practice the technique in class in groups and then use new data (also in groups) for homework as a way of deepening and solidifying their understanding (Paul Alexander Horton, Weiner, and Lande 2018; Neff et al. 2017). In short, each week students are challenged to synthesize the technical knowledge and then apply this learning through a practical data application with questions relevant to the data rather than to the technique. This approach is designed to create a tension between data as viewed by engineers and problems that require a deeper analysis to really understand the contextual story. Throughout the semester, the class pedagogy (and grading) emphasized the importance of characterizing data analysis results within the context in which data emerges. The network class was taught toward the end of the semester, so students had practice with linking data subtleties to context—but only in data reflective of the built environment (e.g., transportation, water, and housing data).
The underlying assumption of most engineering students is that data are data, mostly the same in all applications. Rarely do engineering students grapple with data that are unfamiliar to them. The Humanists on the Move data offered a completely novel opportunity to practice network visualization, motivating students to understand the underlying data in a way that they would not normally worry about.
The engineering class assignment mimicked the instructions for the humanist class, but compressed the time allocated for background research. Each student was assigned three humanists, who themselves were selected because they provided students the opportunity to uncover interesting contextual information. The engineering students prepared a one-page summary of basic background information for each figure, including important acquaintances, and any documented travel using three or more sources of information. Because the time allocated for background research was compressed, Wikipedia was an allowable source of information. It was notable that even this limited information gathering exercise threw engineering students into new terrain. Many had questions about how to decide what was important, how to find sources of information, even why they were working on these data in particular. The exercise of preparing them for the data both energized and confused them.
The engineering students were organized into groups of three. Because each student had background sheets on three humanists, groups were assigned so that each group had multiple sources of information on one or more humanists. This deliberate tactic was intended to motivate them to think more about the information that their networks were conveying. The exercise was structured so that groups started by developing standard networks and then moved to allow each group to design more elaborate or situational networks.
Visualizing Network Data
Each class now visualized the network data. For the engineering students, this was the entire point of the class: to visualize data with the implicit assumption that they would draw on the contextual information that they had gathered prior to the class. For students from art history and other humanities disciplines, this was new terrain. A map is a reasonably familiar object, even from the Renaissance, and students understood all of its basic parameters (Harley 2001). Superimposing information about travels onto it was not in itself a vast step. A network, however, was not something they were used to thinking about in visual form, nor were they adept at analyzing a network. A visible network gathers data and presents it in a way that will suggest new questions and will demand interpretation in and of itself—humanistic interpretation, that will return the uncertain and the variable while also incorporating the regular and quantified.
In engineering, visualization is essential for exploring, cleaning, understanding and explaining data. In the class, students master programming for data visualization that makes data exploration easier and more productive, and allows an engineer to both better understand the data and to present data in a way that has impact, particularly on audiences such as policy makers and the public. Students are taught appropriate (and inappropriate) uses of different kinds of charts and graphs, graphical composition, and the design aspects of effectively conveying information such as selecting colors, minimizing chartjunk and emphasizing key features of the data. The focus in engineering is on the mechanics of visualization. As noted earlier though, the transition to project-based learning in our field has ideally involved preparing students to explore context more deeply, even contexts with which they were truly unfamiliar.
The engineering class used a variety of network packages within R, which is a language that provides an environment for statistics and visualization (R Core Team n.d.). The language is open-source, rooted in statistical computing and provides a reproducible platform for engineering calculations. One of R’s major strengths is that it can be easily extended through packages to include modern computing methods and approaches. The network packages within R that were used in the class included igraph, ggraph, tidygraph, and visNetwork.
The igraph package provides functions that implement a wide range of graphing algorithms and can handle very large graphs (Nepusz 2016). The ggraph package extends ggplot (a core package for visualization) to handle networks using the grammar of graphics approach (Wickham 2010). Next, tidygraph provides tools to manipulate and analyze networks and is a wrapper for most of the igraph capabilities (Pedersen 2020). Finally, visNetwork allows for interactive visualization. Students were given the opportunity to work with any of these tools on this exercise.
The humanities students had started their visualization process using Palladio again. As in its mapping function, Palladio allows for faceting networks, so at this stage students could see all the connections based on friendship, for example, or isolate how and where clerics fit into the network (Figure 3).

Palladio, however, is a tool for visualization and not for computational analysis. It can’t actually work with edge weights, which as humanists we had found to be such an important and complex issue. So at this point the Collaboratory stepped in again with an introduction to Cytoscape. Cytoscape would allow students to visualize the data, while at the same time furnishing a richer understanding of the underlying mathematical analysis of their networks. Cytoscape was developed for analyzing networks of data in systems biology research, as practitioners in this field were not proficient in the use of R (Shannon 2003). As a platform, however, it is discipline-agnostic: data sets of all types and from varied fields, including the humanities, can be analyzed and visualized, and as a result Cytoscape has become a platform researchers in the humanities are comfortable using.
Students were introduced to Cytoscape on the last day of class, and because it was introduced so late in the semester it was advertised as a way for interested students to build another skill and continue querying the dataset they had thus far created and visualized. Students were fascinated by the insights gained from network analyses possible in Cytoscape, but unavailable in Palladio. In addition, they responded favorably to the powerful suite of options within the visualization environment of Cytoscape. For instance, the appearance of nodes and edges can be customized prior to analysis to isolate certain types of values, or the researcher can use the results of statistical analysis to draw out nodes and connections of greater importance within the network. Also of considerable value is the ability of Cytoscape to parse larger datasets, or focus in on specific nodes to make sense of networks within networks, which can be selected and excised into separate visualizations (Figure 4).

Interpreting the Visualized Data
For the humanities students, it was the process and outcome of visualization that made the data intriguing to interpret. But crucially, the data had been created by them, over a period of months, before they could move ahead with visualizing and interpreting it. It was only then that they could see, for instance, that certain thinkers held key positions between powerful figures while others, extremely famous in our day, were on the margins of the main humanist network. Persons who wrote a great deal, be it sermons or conduct books or even letters, might have an enormous “degree centrality” (or number of connections), even while the edge weight of many of their connections was relatively low. Some secondary figures who we would have thought to be quite outside our network assumed rather central positions in it. What, we asked, should we make of these unexpected findings?
Because students had developed the data themselves, and had in the process become very familiar with individual figures within the network, they were better able to interpret the positions of each major person. And because of their previous experience with mapping, they had extra knowledge that informed their interpretation of the network. For instance, a figure who travelled very little—say, Raphael—was hampered in his network-building despite his enormous historical influence. This led the class to question both their art-historical preconceptions—for example, that as a superstar, Raphael would be at the center of a network—but also to pose further humanistic questions that the data could not answer. Network-building was crucial for some figures (Aretino springs to mind) but of limited importance for others. What were the alternatives? Creating, visualizing, and then interpreting data was a means of creating new knowledge and a stimulus to further thinking. This further thinking was based on humanistic knowledge and posed questions that would be answered through those means. The shuttle back and forth between quantifiable data and humanistic inquiry through data and its visualization was a hugely fruitful exercise (Drucker 2011).
While producing reasonably well-designed networks, the engineering students studiously avoided connecting networks to a more textual analysis. For example, Figure 5 on the left shows the most common output (from ~90% of the groups) when students were asked to portray the network (an open-ended question). When asked to focus on one or more attributes, every group produced a gender network (Figure 5 on the right). This happened despite the relative abundance of other types of attributes and of group and individual knowledge specific to each of the humanists.

Conclusion
Humanists were challenged by the idea of extracting data from context, taking facts (“Do we believe in facts in this class?” one student had asked) and turning them into quantifiable data. The more they discretized and structured the data, the more resistant they became to compromise, to what they perceived as flattening out the nuance of individual relationships or even professional identities. However, once the data were visualized, class members were well prepared to read those results and return them to a humanist framework. Without caring particularly how the networks themselves looked, they approached the data with a more historically informed eye than did the engineers and moved quickly to interpretation. For instance, they already knew well the limitations on women’s travel and connections—we had read primary sources about women’s education—and so that and other historical aspects of the network were more revealing to them.
Much of engineering pedagogy focuses on design techniques to solve a problem. In the engineering R class, the design techniques were tuned toward learning about visualization (e.g., color ramps), how to code and design visualization features that draw attention to features of the visualization that are relevant to the analytical objective. This approach to the exercise resulted in networks that lacked texture, despite the interesting and often provocative information on the humanists that students gathered prior to the class. Engineers tend to gravitate toward well-produced visualizations (e.g. appropriately labeled axes, titles that are descriptive, etc.) or portray some important design feature. When the data cannot be understood without context, engineers are less able to navigate the tension between accuracy and context.
Engineers are, however, more alert to the subtleties of the visualization itself and how it communicates information about the data. The caveat here is that the engineering students seem unable to bring noted visualization subtleties back to the data context. In other words, they produce beautiful graphics but do not reflexively use these visualizations to think more about the problem from which their data emerges. Alternatively, humanists, even art historians, have not been trained to care about the aesthetic and persuasive presentation of data. Perhaps this is because humanists see themselves as talking mostly with one another, moving rather quickly from visualized data back to humanistic queries and a written argument. It may be that the humanist students need to be formally trained to make their visualizations an integral part of their textual analysis story. It might also be useful to the future of the humanities, particularly a public-facing humanities, if humanists were not only more comfortable with data, but also with using it to speak beyond the confines of the classroom or the pages of a scholarly journal.