Rochelle (Shelley) Rodrigo, Old Dominion University
Abstract
Instructors teaching research methods, especially undergraduate writing courses that focus on researched arguments, should use various web-based interactive applications, usually referred to as Web 2.0 technologies, throughout the research process. Using these technologies helps students learn various 21st Century technology and media literacies as well as promote diverse student learning methods and active learning pedagogies. The article provides examples of different type of web-based applications that might be used throughout the research process and then ends with a discussion of logistical concerns like student access and privacy rights.
Admit it, when you first search for something you use Google or check Wikipedia:
- Of course!
- What? Are you crazy! I can’t trust those sites.
- I shout out to Facebook or Twitter.
- Plead the fifth.
I don’t ask this question of my students; instead, I ask this question of my colleagues when I do workshops about teaching with technology (especially when teaching big end-of-semester term or research papers). Can you guess the results? If we admit that we are just as “guilty” of using Google or referring to Wikipedia and other online “friends” when seeking out information, isn’t it time we accept these as legitimate steps for research in the 21st century. Therefore, if going to the web is the one of the first steps for research, we should “digg” using various web applications when teaching research skills.
Digg is the catchy title for thinking about using web applications in research. On the one hand, I believe instructors do not use social bookmarking tools, like Digg, nearly enough while teaching basic research skills, especially in First Year Composition courses. However, I do not use Digg, nor ask my students to use Digg, because it has been repeatedly critiqued for the gender, age, and socioeconomic bias of the users who curate the materials (Lo 2006; Solis 2009; Weinberg 2006). Digg’s biased user population is representative of the promise and peril of the internet in general. If anyone can post on Digg, and I choose to use such a web application in my research, how does the bias of the application impact my research process and product. However, is that not the case with almost any research process and product we suggest for our students? In short, part of what we are teaching our students about research is to just be plain critical, of everything, including the tools we use (Selfe 1999).
Critical engagement with the technologies they use is a powerful motivator for having students work with various web applications. Learning how to use different technologies, learn new technologies and critically engage with technologies prepares students for staying successfully employed in the 21st century. The majority of lists citing the key skills needed to succeed in the 21st century include “information literacy” as well as “consume and compose multimedia.”(AT&T 2010; CWPA 2008; Partnership for 21st Century Skills n.d; NCTE 2008; Kamenetz 2010).
Lankshear and Knobel (2007) claim that:
The more a literacy practice that is mediated by digital encoding privileges participation over publishing, distributed expertise over centralized expertise, collective intelligence over individual possessive intelligence, collaboration over individuated authorship, dispersion over scarcity, sharing over ownership, experimentation over ‘normalization’, innovation and evolution over stability and fixity, creative innovative rule breaking over generic purity and policing, relationship over information broadcast, do-it-yourself creative production over professional service delivery, and so on, the more sense we think it makes to regard it as a new literacy. (228)
If the Web 2.0 world is promoting these types of changes, researching in the Web 2.0 world might need to be considered a new literacy.
This article argues that instructors teaching research methods, especially undergraduate writing courses that focus on researched arguments, should use various web-based interactive applications. The article discusses how these applications, usually referred to as Web 2.0 technologies, are a way to meet 21st Century Literacies learning objectives as well as diversify student learning methods and facilitate active learning pedagogies. The article then provides examples of different types of web-based applications that might be used throughout the research process, and ends with a discussion of logistical concerns like student access and privacy rights.
Why Digg It?
Once you get out into the real world you won’t have your textbooks with you, so having experience using IT as a learning tool helps prepare people for life after textbooks.
–An undergraduate student, 2010 ECAR Study of Undergraduate Students and Information Technology (Smith and Caruso 2010, 27)
The obvious first reason for teaching students to use web applications in research is “if you can’t beat them, join them.” I know students are going to use Google; therefore, I embrace that default and enjoy introducing them to specialized Google search engines like Google Scholar (Google’s search engine that focuses on returning results from scholarly books and journals), Google Books (Google’s search engine that returns results from Google’s book scanning project), and Google News (Google’s search engine that returns results from news outlets as far back as the 19th century). I enjoy their “shock” in learning about these specialized search engines.
Since 2004, college students responding to the annual ECAR Study of Undergraduate Students and Information Technology have rated themselves highly for the ability to “use the Internet effectively and efficiently search for information” (Smith and Caruso 2010, 66). Specifically in 2010, 80.7% gave themselves “high marks (expert or very skilled)” and over 56% gave themselves high marks for “evaluating reliability and credibility” (69). However, if students are as information literate as they think, then why does it feel like there is a “crisis” of 21st Century Literacies? Although it feels like the “crisis” of 21st Century Literacies is restricted to the 21st century, the heart of this crisis is wrapped up in various techno-literacies and the various media or techno-literacy crises have been rampant for over 40 years. Since the National Council of Teacher’s of English (NCTE) published the “Resolution on Media Literacy” in 1970, it has followed up with a variety of other related lists and position statements about techno-, media, and 21st century literacies.
Many other educational organizations produce lists and policy statements that include things like:
- using technology to gather, analyze, and synthesize information (ASCD 2008; Association of Colleges and Research Libraries 2000; Council of Writing Program Administrators [CWPA] 2008; National Council of Teachers of English [NCTE] 2008; & Partnership for 21st Century Skills n.d.) as well as
- describe, explain, and persuade with technology (Conference on College Composition and Communication 2004; CWPA 2008; Intel n.d.; NCTE 2005; NCTE 2008; & Partnership for 21st Century Skills n.d.).
Forbes’s top 10 list of “skills that will get you hired in 2013” listed “computers and electronics” as number five; the top two skills listed were “critical thinking” and “complex problem solving” (Casserly 2012)—both required of major research and writing projects. Teaching research processes through and with web 2.0 technologies combines these skills. In a study of basic writing students, Vance (2012) found that although students do want the interactivity that comes with Web 2.0 technologies, they also want more stable, instructor vetted and delivered content as well. This desire hints at the fact students do want and need help identifying and using digital information. Instructors are being hailed by both (the overestimation of) their students as well as (the underestimation of) their colleagues to help students become better technologically-mediated researchers and communicators.
Getting students to understand that there is more to Googling than just Google not only helps develop more critical digital research skills, it builds upon what they already know and do. Most individuals do some form of research every day, and more often than not, Google does get the job done. Starting with what the students already do works not only because we are going with the flow; actually, it is because it is going with their flow. Brain research demonstrates that students learn best when what they learn is connected to something they already know or do (Leamnson 1999; Zull 2002). The process of teaching research skills needs to be built upon students’ existing processes. Instead of trying to completely rewire students–as science instructors often attempt to do when they continually repeat that seasons are based on the position of the earth’s axis and not its proximity to the sun–help them adapt and expand their already hardwired “Google it” response. A number of scholars have published that various Web 2.0 applications support research-related activities like reading (Won Park 2013) and finding and evaluating information (Magnuson 2013), and are compatible with learning pedagogies such as constructivism (Paily 2013), connectivism (Del Moral, Cernea, and Villalusttre 2013), and problem-based learning (Tambouris et al. 2012).
Increasingly, both scholarly as well as more plebian research resources are only available in digital formats, usually accessible through the web. Students not only need to learn how to (systematically) search for these resources, they need to learn to critically consume different types of resources, some with no written words. Once students find and read these resources, they also need help collecting, archiving, and analyzing them as well. Finally, with the variety of available digital publication media, students can contribute back by producing multimedia projects as they report out on their research process and product.
What are You Digging With?
Scholarship in composition and literacy studies has demonstrated as a field composition studies supports using web-based interactive communication applications, many referred to as Web 2.0 technologies, in the teaching and learning of writing. Strickland (2009) claims “writers should be able to use all available technology to help them discover what and how to say what needs to be written” (p. 12). Many of these web-based applications either “count” as the multimodal compositions that scholars like Takayoshi and Selfe (2007) as well as organizations like NCTE (2005) and CCCC (2004) promote or help produce those same multimedia texts. Even English education programs, like the one discussed in Doering, Beach and O’Brien (2007) promote teaching future English teachers about using different web-based applications. Most of the time, however, these discussions about using various web-based technologies are focused on the product of a student’s major research project. Many of these technologies can also support the writing process as well as the research process. The mistake that many instructors make in thinking about incorporating multimedia and web applications in the research process is only focusing on the products of research—the primary, secondary, or tertiary resources incorporated into research or the “report” out of the research. Successful 21st century researchers need to think about using various web applications and embracing multimedia throughout the entire research process:
- Identifying a Topic
- Finding & Collecting Resources
- Critically Reading & Evaluating Resources
- Synthesizing Ideas & Resources
- Drafting & (Peer) Reviewing
- Presenting Final Results
For example, instructors may only think that YouTube (a video repository where individuals can make accounts and upload videos to share) is only good for finding questionable resources and presenting final projects in video form. However watching videos on YouTube, Vimeo, or TED might help students struggling to find a topic that interests them or see how people are currently talking about a specific topic. It is definitely time to rethink “YouTube is a bad resource” just because anyone can post a video; will anyone question the scholarly veracity of one of Michael Wesch’s digital anthropology videos? YouTube can also help solve common formatting problems as well. Instead of using time in class showing students how to do headers and hanging indents in their final research papers; assign as homework a YouTube video demonstrating how to do the formatting functions in different version of MS Word or OpenOffice.
Ultimately the goal for this article is to outline examples of what types of web applications might be incorporated at various points within a traditional (primarily secondary) research process. First, getting students to produce and share texts through the research process helps them keep connected with an audience. Second, producing digitized final projects that are published to the web, especially multimedia projects, makes students’ work refrigerator door worthy; you know, like the finger paintings we brought home from preschool. And Facebook is the new refrigerator door, instantly giving students a real audience with real feedback that they care about.
Applications to Help Identify a Topic
Getting students started on a research project is always more difficult than expected. At the beginning of a research project students generally need to identify a topic that is engaging to them as well as narrow it down to something unique. In both cases, students need help thinking differently about their interests. As Brooke (2009) suggests, researchers should understand search results as “departure points, that bring potentially distant topics and ideas in proximity both with each other and the user” (83). Sometimes it just helps to provide them with a variety of alternative search engines (anything besides the general Google search engine) and media repositories (image, audio, video, and text) to help identify what interests them. Many students do not pay attention to the variety of ways they may filter search results in the left hand menu of a Google search results page nor know that Google has specialized search engines like Scholar, Books, and News. Although the web is full of personal rants and raves, those non-scholarly resources, like personal blogs and wikis (including Wikipedia), can be extremely useful in helping students further narrow a topic to something manageable and with a unique angle as well as analyze what they already know or believe about the topic. Using search engines that present the search results visually (for example: Cluuz, Hashtagify, Search-Cube, or TouchGraph) can also help with narrowing a topic as well as preparing a list of future search terms (figure 1).

Figure 1: Results from a Cluuz search; multiple visual cluster maps presented on the right side of the page.
In short, the varied web resources provide students the opportunities to both explore as well as narrow their research topics. Introducing students to advanced search pages or results filters will not only help them identity interesting, focused research topics, it will help them find relevant secondary resources as well.
Applications to Help Find & Collect Resources
Teaching students to find resources is generally easier than helping students collect the resources they find. Based on my experience, robust citation management applications like Zotero, Mendeley, or EndNote have a steep learning curve for users to understand both the citation management as well as note taking functionalities. The time to learn the various aspects of the applications usually requires more time than available in freshman and sophomore level classes with major research projects. Instead of using these more complex applications, students can use social bookmarking sites, like Delicious and Diigo (usually easier to learn than full resource collecting programs), to keep track of their resources. Social bookmarking sites collect users saved webpage URLs. Except, instead of being restricted to one computer, like when saved using My Favorites in the Internet Explorer browser, social bookmarking sites save the list of links to a server the user can access from any computer connected to the web. Most social bookmarking sites also allow the user to associate notes with each bookmarked webpage.
Even if students are collecting books they found at the library or journal articles they found in a library database (resources that are not normally associated with a webpage), they can bookmark WorldCat’s or the library’s webpage representing the book (figure 2) and link to the permalink, or deeplink, into a library database resource. Johnson (2009) explicitly argues that using different Web 2.0 technologies, like blogs and social bookmarking, allow students to more readily collect both their secondary as well as primary resources. The amount of detail included with the bookmarked resource is only limited to the assignment requirements given to a student. An instructor can ask a student to include information like a bibliographic citation, summary, and source evaluation in the “notes” area of the social bookmark for each resource (figure 2).

Figure 2: An example of a robust annotated bibliography entry in the social bookmarking application Diigo.
Since they are social, social bookmarking sites are by default public and make it easy for students to share resources with one another, or their instructors. Social bookmarking sites will also help students find more resources. They can find individuals who have bookmarked the same resources and identify other resources. Students can also identify how individuals tagged resources with identifying keywords, like indexing, and use those tags as alternative key words in more searches in databases and other locations. As web-based applications, social bookmarking sites also address some access issues; students who do not have regular access to the same computer can still store all of their collected resources in one online repository that they can get to from any computer with an Internet connection.
Applications to Help Critically Read & Evaluate Resources
More sophisticated social bookmarking tools like Diigo also allow students to read and annotate web resources (applications like A.nnotate and Internote also allow web page annotations). Diigo allows users to highlight and leave post-it styles notes on most webpages (figure 3).
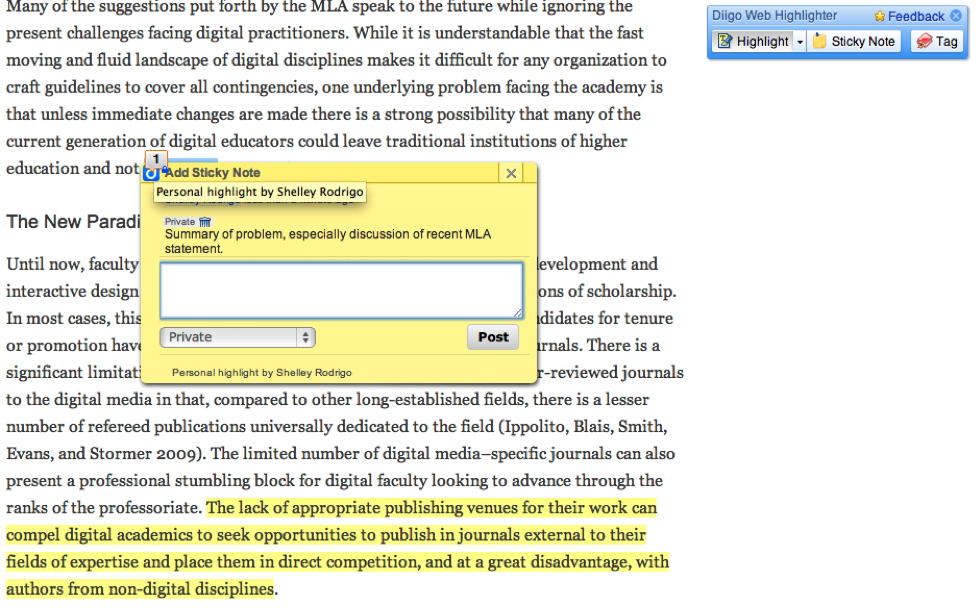 Figure 3: Example of Diigo highlight and “post-it” note style annotation tools.
Figure 3: Example of Diigo highlight and “post-it” note style annotation tools.
Having the ability to take notes does not inherently prompt students to be critical readers, instead a functionality that enables commenting might prompt students to ask what type of questions and comments should the annotated on their resources. English faculty, or librarians, can provide students with a list of resource evaluation questions that students might then answer by highlighting and taking notes on the page. Since Diigo is a web application, students can share their annotated resource with other students or the instructor.
Applications to Help Synthesize Ideas & Resources
Once students’ notes are digital, it is easy for them to slide them around, looking for connections to help synthesize ideas and resources. Again, these web applications do not inherently make students engage their resource materials in more sophisticated ways; instead, these resources provide students with the opportunity to engage with and connect their resources differently. Writing instructors have asked students to make mind or cluster maps of their research topic, resources, and ideas for decades; however, having students make these in a web application allows for more detailed information associated with each node. Many of the digital mind map applications (like Mindomo and Popplet) allow users to include text, images, videos, even attachments to each individual node of information. Many mind map applications also allow users to collaborate, sometime even synchronously, within the same document. A team of students working on a research project could collaboratively construct a mind map with the different resources each individual located. Timeline and geographical mapping applications, web applications that allow users to map information as a point in time or geo-spatially, also allow students to interact with their resources and data in different ways (figure 4).

Figure 4: Example of a timeline showing various organizational statements about 21st Century Literacies.
Having students play with their resources and data forces them to spend time with their resources and data. Ultimately, it is that time with the data that helps students the most in synthesizing information in a meaningful way.
Applications to Help Draft & (Peer) Review
Students should be drafting and getting feedback along the entire research process. One of the standard functions of various Web 2.0 applications, also regularly referred to as read/write web, is some form of interaction between the many kinds of readers and writers (Dilager 2010). Even as early in the process as identifying and narrowing a topic, students should be able to share their narrowed topic or research question and possibly make a research plan. In either case, students will want feedback about their work. Microblogs, like Twitter and the Facebook Status Update, give students the opportunity to gather quick feedback on material as small as a research question or thesis statement.
There are a variety of read/write web applications students might use to report out and invite feedback of all amounts during their research projects. Blogs, wikis, and document sharing applications like Google Drive would allow students to document large portions of their research process and product. These popular applications are also probably the best known and most written about web applications to support the teaching of writing, especially as a way to expand audience feedback and participation with a given project (Alexander 2008; Johnson 2009; Nakamura 2011). Blogs, wikis and document sharing are usually structured to facilitate some form of a social network that invites “replies” to any posted work. Some advanced feedback applications allow readers to respond to specific sections of a draft. For example, the CommentPress Core plugin for a WordPress blog allows readers to comment on individual paragraphs as well as an entire posting. Similarly, VoiceThread allows viewers to comment on individual presentation slides as well as draw on an individual slide to reference a specific area of a visual.
Not just text based web applications facilitate replies to content; even the more visual Web 2.0 applications where students might post parts of their research usually include spaces for readers to make comments. Most image and video repositories usually have reply features. Even if students are publishing their work in progress or request for feedback in different locations, using microblogs can help them to send out requests for feedback with links to where ever the material is residing. In short, there is no technological reason not to request and receive feedback throughout the entire research process.
Applications to Help Present Final Results
Many of the applications mentioned above might also be used as final presentation formats or media. Document sharing would allow for easy publishing of traditional paper style presentations. And if students were blogging their entire research process, they can post their final presentation as the last post (however, the first visible to visitors) on their research blogs. Students might use alternative visual presentations applications like Prezi to distinguish themselves from the masses that use PowerPoint. However, there are a many Web 2.0 applications not discussed in this article that would allow students to get really creative with their final product. With all the freely available web 2.0 applications mentioned in this article or listed at websites like Go2Web20 and Discovery’s Web 2.0 Tools, students could produce a variety of media including audio or video files, timelines or maps, digital collages or mind maps.
Asking students to produce their final presentations in these alternative formats does not necessarily relieve them of the rhetorical responsibilities of a composition class (Takayoshi and Selfe 2007). Asking students to write cover memo identifying their purpose, audience, and other rhetorical factors as well as discussing how their project meets those rhetorical factors reengages students with their rhetorical responsibilities.
How to Digg It?
Beyond thinking about how to use the technologies, many instructors have two major concerns about incorporating any technology into their assignments: access and support. Although these are both legitimate concerns, the digital divide is alive and well in the second decade of the 21st century (Jansen 2010), the need to creatively overcome these concerns meets the objective of making our students more technologically savvy. In other words, most individuals face some form of technological access and support issue on any digital project. Putting students into groups for assignments, even if they are just support and peer review groups for research projects, resolves a lot of access and support issues. Constructing student groups as collaborative learning communities empowers them to share knowledge and resources, including “access” to specific types of needed hardware and software and the skills to use it. Having students understand that finding and learning how to use a specific technological application is both another example of research as well as a skill they will need to continue to hone with how fast both hardware and software updates and evolves. If a given Web 2.0 application’s help page is not helpful, and the group can’t figure it out how to use the program, YouTube is always a good place to look for help with any “how-to” question. And if there is still no answer on YouTube, maybe it is time for instructors to make a few “how-to” videos and post them up to YouTube.
Another concern that faculty, administrators, and scholars have about using web applications in classes is privacy, especially in relation to legal issues like the Family Educational Rights and Privacy Act, FERPA (Diaz 2010; Ellison and Wu 2008; Rodriguez 2011). Although many of the web applications I discuss above have privacy options, more conservative interpretations of FERPA argue that students rights are not protected since the school does not have an officially signed legal contract with the application provider. There is no one easy solution to the FERPA issue; however, honesty is the best policy. I have discussed using these types of applications with the legal personnel associated with my institution. With their help, I’ve added a section to my syllabus about using web applications (Appendix). In short, this section notifies students of their legal rights to privacy and legal responsibilities like copyright infringement; it also provides them an alternative option that is not posted to the Internet. Of course, the alternative option is the traditional research process and paper; however, to date, I have never had a student take the alternative option. I have had an increasing number, still a very small number, choose to password protect their work; however, no one has refused to use the web application.
Long-term access and archiving are final concerns with using web applications for academic assignments. It is true that individuals or companies maintaining different web applications go out of business and can no longer support the website. For example, I once had a student construct a beautifully researched and documented timeline and then the company supporting the timeline application stop supporting the service. Similarly, I’ve had classes of students develop mind maps in mindmeister for free before mindmeister canceled their free accounts; those mind maps are now inaccessible (unless the student pays for them). Again, instead of using this as an excuse, it can be a “learning moment” to have discussions with students about archiving their work in an alternative format. At minimum, it is relatively easy to either take static or dynamic screen captures to save images or video of student work. Consider having students use free screen capture software, like Jing or Screencast-O-matic, to report out and reflect upon their work as a part of their assignment. The could make a five minute video, or two, that introduces the project, discusses their rhetorical choices, and reflects upon the process of constructing the text. This reflective screen capture video assignment does double-duty in archiving their work in an alternative format.
Interestingly enough, many educational institutions or educational technology companies have tried to address issue like FERPA and archiving by developing their own versions of Web 2.0 applications, like Purdue University’s relatively successful Hotseat and Blackboard’s incorporation of blogs, wikis, and social media like interfaces into their learning management system software. However, I agree with Jenkins (2008) and Dilager (2010) that replicating services is generally not a good idea. Most homegrown technologies never work as well as the “original” and other institutional issues about continued command, control, and support emerge. Instead, Dilager argues for a “critical engagement with Web 2.0” (24), implying that both faculty and students should consider the original purpose and authors/companies producing the Web 2.0 applications they are using. For example, Facebook is a service for profile application (the service is free because the application mines profile information and sells it to other companies). Faculty should understand Facebook’s commercial element before requiring students to use the application. This type of critical engagement brings us full circle to the issue of user/curator bias in Digg, just as with evaluating research resources, faculty and students should evaluate the technologies they choose to use.
Although there are a variety of reasons that might make it difficult to incorporate different interactive web-based, Web 2.0, applications into undergraduate research courses, the benefit of having more engaged students as well as more critical and complex researched projects is worth the work. Providing students with a scaffolded project that asks them to engage with these different technologies helps prepare them for the variety of research processes they will undertake in their future academic, professional, and civic lives.
Bibliography
Alexander, Bryan. 2008. “Web 2.0 and Emergent Multiliteracies.” Theory Into Practice 47(2): 150-160. OCLC 424874670.
ASCD. 2008. “21st Century Skills.” ASCD. Accessed September 5, 2013. http://www.ascd.org/research-a-topic/21st-century-skills-resources.aspx.
Association of Colleges and Research Libraries. 2000. “Information Literacy Competency Standards for Higher Education.” Association of Colleges and Research Libraries. Accessed September 5, 2013. http://www.ala.org/acrl/standards/informationliteracycompetency.
AT&T. 2010. “21st century literacies: http://www.kn.pacbell.com/wired/21stcent/.” Internet Archive Wayback Machine. Accessed May 31, 2013. http://web.archive.org/web/20110716160908/http://www.kn.pacbell.com/wired/21stcent/
Brooke, Collin Gifford. 2009. Lingua Fracta: Toward a Rhetoric of New Media. Cresskill, NJ: Hampton Press. OCLC 366469179.
Casserly, Meghan. 2012. “The 10 Skills That Will Get You Hired in 2013.” Forbes, December 10. http://www.forbes.com/sites/meghancasserly/2012/12/10/the-10-skills-that-will-get-you-a-job-in-2013/.
Conference on College Composition and Communication. 2004. “CCCC Position Statement on Teaching, Learning, and Assessing Writing in Digital Environments.” National Council of Teachers of English. Accessed June 1, 2013. http://www.ncte.org/cccc/resources/positions/digitalenvironments.
Council of Writing Program Administrators. 2008. “WPA Outcomes Statement for First Year Composition.” Council of Writing Program Administrators. Accessed June 1, 2013. http://wpacouncil.org/positions/outcomes.html.
Del Moral, M. Esther, Ana Cernea, and Lourdes Villalustre. 2013. “Connectivist Learning Objects and Learning Styles.” Interdisciplinary Journal of E-Learning and Learning Objects 9: 105–124. http://www.ijello.org/Volume9/IJELLOv9p105-124Moral0830.pdf.
Diaz, Veronica. 2010. “Web 2.0 and Emerging Technologies in Online Learning.” New Directions for Community Colleges 150: 57-66. OCLC 650836072.
Dilager, Bradley. 2010. “Beyond Star Flashes: The Elements of Web 2.0 Style.” Computers and Composition 27(1): 15-26. OCLC 535530420.
Doering, Aaron, Richard Beach, and David O’Brien. 2007. “Infusing Multimodal Tools and Digital Literacies into an English Education Program.” English Education 40(1): 41-60. OCLC 424828004.
Ellison, Nicole B., and Yuehua Wu. 2008. “Blogging in the Classroom: A Preliminary Exploration of Student Attitudes and Impact on Comprehension.” Journal of Educational Multimedia 17(1): 99-122. OCLC 425163509.
Intel. n.d. “Technology Literacy.” Intel. Accessed September 5, 2013. http://www.intel.com/content/www/us/en/education/k12/technology-literacy.html.
Jansen, Jim. 2010. Use of the Internet in Higher-income Households. Pew Internet. Accessed June 1, 2013. http://www.pewinternet.org/Reports/2010/Better-off-households.aspx.
Jenkins, Henry. 2008. “Why Universities Shouldn’t Create ‘something like YouTube’ (Part One).” Confessions of an Aca-Fan (blog). Accessed June 1, 2013. http://henryjenkins.org/2008/10/why_universities_shouldnt_crea.html.
Johnson, Mary J. 2009. “Primary Sources and Web 2.0: Unlikely Match or Made for Each Other?” Library Media Connection, 27(4): 28-30. OCLC 425516321.
Kamenetz, Anya. 2010. DIY U: Edupunks, Edupreneurs, and the Coming Transformation of Higher Education. White River Junction, VT: Chelsea Green Publishing Company. OCLC 449895015.
Lankshear, Colin, and Michele Knobel. 2007. “Researching New Literacies: Web 2.0 Practices and Insider Perspectives.” E-Learning 4(3): 224-240. OCLC 593828824.
Leamnson, Robert. 1999. Thinking about Teaching and Learning: Developing Habits of Learning with First Year College and University Students. Sterling, VA: Stylus. OCLS 39671176.
Lester, Jim D, and James D. Lester. 2012. Writing Research Papers 14th edition, New York: Pearson. OCLS 746477415.
Lo, Ken. 2006. “Digg political bias.” Ken’s Tech Tips: Helping you to get the most out of Modern Technology and Communications since 2004 (blog). Accessed June 1, 2013. http://cow.neondragon.net/index.php/1607-Digg-Political-Bias.
Magnuson, Marta L. 2013. “Web 2.0 and Information Literacy Instruction: Aligning Technology with ACRL Standards.” The Journal of Academic Librarianship 39 (3) (May): 244–251. OCLC 4950915526.
Miller-Cochran, Susan K., and Rochelle L. Rodrigo. 2014. The Wadsworth Guide to Research 2nd edition, Boston: Wadsworth. OCLC 847942780.
Nakamura, Sarah. 2011. “Making (and not making) Connections with Web 2.0 Technologies in the ESL Classroom.” TETYC 38(4): 377-390. http://www.ncte.org/journals/tetyc/issues/v38-4.
National Council of Teachers of English. 2013. “21st Century Literacies.” National Council of Teachers of English. Accessed September 5, 2013. http://www.ncte.org/positions/21stcenturyliteracy.
National Council of Teachers of English. 2005. “Position Statement on Multimodal Literacies.” National Council of Teachers of English. Accessed June 1, 2013. http://www.ncte.org/positions/statements/multimodalliteracies.
National Council of Teachers of English. 1970. “Resolution on Media Literacy.” National Council of Teachers of English. Accessed September 5, 2013. http://www.ncte.org/positions/statements/medialiteracy.
National Council of Teachers of English. 2008. “The NCTE Definition of 21st Century Literacies.” National Council of Teachers of English. Accessed June 1, 2013. http://www.ncte.org/positions/statements/21stcentdefinition.
Paily, M.U. 2013. “Creating Constructivist Learning Environment: Role of ‘Web 2.0’ Technology.” International Forum of Teaching and Studies 9 (1): 39–50. http://www.americanscholarspress.com/content/IFOTS-One-2013.pdf.
Palmquist, Mike. 2012. The Bedford Researcher 4th edition, Boston: Bedford/St. Martins. OCLC 726822778.
Partnership for 21st Century Skills. n.d. “Framework for 21st Century Learning.” Partnership for 21st Century Skills. Accessed June 1, 2013. http://www.p21.org/overview/skills-framework.
Rodriguez, Julia E. 2011. “Social Media Use in Higher Education: Key Ares to Consider for Educators.” MERLOT Journal of Online Learning and Teaching 7(4). http://jolt.merlot.org/vol7no4/rodriguez_1211.htm.
Selfe, Cynthia L. 1999. “Technology and Literacy: A Story about the Perils of Not Paying Attention.” College Composition and Communication 50(3): 411-436. OCLC 425570905.
Smith, Shannon D., & Judith Borreson Caruso. 2010. The ECAR Study of Undergraduate Students and Information Technology, 2010. EDUCAUSE. Accessed June 1, 2013. http://www.educause.edu/ers1006.
Solis, Brian. 2009. “Revealing the People Defining Social Networks.” @ Brian Solis (blog). Accessed June 1, 2013. http://www.briansolis.com/2009/10/revealing-the-people-defining-social-networks/.
Strickland, James. 2009. “Writer’s World 2.0: The Times They are a’changin’.” English Leadership Quarterly 32(1): 12-14. http://www.ncte.org/journals/elq/issues/v32-1.
Takayoshi, Pamela, and Cynthia L. Selfe. 2007. “Thinking about Multimodality.” In Multimodal Composition: Resources for Teachers, edited by Cynthia L. Selfe, 1-12. Cresskill, NJ: Hampton Press, Inc. OCLC 77572962.
Tambouris, Efthimios, Eleni Panopoulou, Konstantinos Tarabanis, Thomas Ryberg, Lillian Buus, Vassilios Peristeras, Deirdre Lee, and Lukasz Porwold. 2012. “Enabling Problem Based Learning through Web 2.0 Technologies: PBL 2.0.” Educational Technology & Society 15 (4): 238–251. OCLC 828866668.
Vance, Lash Keith. 2012. “Do Students Want Web 2.0? An Investigation into Student Instructional Preferences.” Journal of Educational Computing Research 47 (4) (January 1): 481–493. OCLC 828867225.
Weinberg, Tamar. 2006. “What I don’t like about Digg.” Technipedia (blog). Accessed June 1, 2013. http://www.techipedia.com/2006/what-i-dont-like-about-digg-bias/.
Won Park, Seung. 2013. “The Potential of Web 2.0 Tools to Promote Reading Engagement in a General Education Course.” TechTrends 57 (2): 46–53. OCLC 846499361.
Zull, James E. 2002. The Art of Changing the Brain: Enriching the Practice of Teaching by Exploring the Biology of Learning. Sterling, VA: Stylus. OCLC 49673202.
Appendix: Sample Syllabus Language
This is the syllabus language I have negotiated with the lawyers at my former institution. To be legally “binding,” I have to obtain some form of “signed” response.
We will be using a web-based timeline application (TimeGlider) for academic use in ENG101, First Year Composition, section #####, Fall 2009. By default, the timeline is open to the public for the purpose of sharing your work with the larger Internet community; specifically, using the timeline application will:
- provide an opportunity to present information in a variety of modalities,
- allow students to conceptualize their projects in a chronological manner,
- provide an opportunity to collaborate on large scale projects, and
- engage a larger audience who may provide feedback on the project.
To use the timeline application responsibly please observe all laws, MCC, and MCCCD policy that are incorporated into the Codes of Conduct and Academic Integrity. Some specific aspects of law and policy that might be well to remember are prohibitions against copyright infringement, plagiarism, harassment or interferences with the underlying technical code of the software. Some resources to remind yourself about MCC and MCCCD policies as well as laws about copyright and fair use:
As a student using the timeline application certain rights accrue to you. Any original work that you make tangible belongs to you as a matter of copyright law. You also have a right to the privacy of your educational records as a matter of federal law and may choose to set your timeline privacy settings to private and only share with the instructor and your classmates. Your construction of a timeline constitutes an educational record. By constructing a timeline, and not taking other options available to you in this course equivalent to this assignment that would not be posted publicly on the Internet, you consent to the collaborative use of this material as well as to the disclosure of it in this course and potentially for the use of future courses.
About the Author
Rochelle (Shelley) Rodrigo is Assistant Professor of Rhetoric & (New) Media at Old Dominion University. She was as a full time faculty member for nine years in English and film studies at Mesa Community College in Arizona. Shelley researches how “newer” technologies better facilitate communicative interactions, more specifically teaching and learning. As well as co-authoring the first and second editions of The Wadsworth Guide to Research, Shelley was also co-editor of Rhetorically Rethinking Usability (Hampton Press). Her work has also appeared in Computers and Composition, Teaching English in the Two-Year College, EDUCAUSE Quarterly, Journal of Advancing Technology, Flow¸ as well as various edited collections.