What can data visualization tell us about the scope and spread of Pan-Africanism during the first half of the 20th century, and what insights does undertaking this research offer for teaching data literacy? These questions were at the heart of a directed study during the 2019–2020 academic year, where we, a professor (Roopika Risam) and two students (initially Jennifer Mahoney in Fall 2019, with Hibba Nassereddine joining in Spring 2020), examined the utility of data visualization for African diaspora digital humanities and its possibilities for cultivating students’ interest in and knowledge of data-driven research. Part of Mahoney’s participation in Salem State University’s Digital Scholars Program, which introduces students to humanities research using computational research methods, the directed study offered her the experience of undertaking interdisciplinary independent research (a rare opportunity in the humanities at Salem State University), an introduction to working with data and data visualization, and the opportunity to broaden her knowledge of African diaspora literature and history. While the process of undertaking this research included many twists and turns and, ultimately, did not yield the insights we had anticipated, it opened up new areas of inquiry for computational approaches to the African diaspora, critical insights about the value of introducing students to African diaspora digital humanities, and the pedagogical imperatives of data literacy. As we propose, data projects on the African diaspora offer the possibility of both introducing students to important stories and voices that are often underrepresented in curricula and to the ethics of working with data in the context of communities that have been dehumanized and oppressed by unethical uses of data.
The State of Data in African Diaspora Digital Humanities
In recent years, Black Digital Humanities has grown tremendously in scope. The African American Digital Humanities (AADHum) Initiative at the University of Maryland, College Park, led initially by Catherine Knight Steele and now by Marisa Parham, and the Center for Black Digital Research at Penn State, led by P. Gabrielle Foreman, Shirley Moody-Turner, and Jim Casey, attest to increased institutional investment in digital approaches to Black culture. An extensive list of projects, created by the Colored Conventions Project, demonstrates the variety of methodologies, histories, and voices being explored through Black Digital Humanities scholarship. Since Kim Gallon outlined the case for Black Digital Humanities in her essay in the 2016 volume of the Debates in the Digital Humanities series, she has, indeed, “set in motion a discussion of the black digital humanities by drawing attention to the ‘technology of recovery’ that undergirds black digital scholarship, showing how it fills the apertures between Black studies and digital humanities” (Gallon 2016, 42–43). Black Digital Humanities is, as scholars like Gallon (2016), Parham (2019), Safiya Umoja Noble (2019), and others propose, fundamentally transnational. An emphasis on the African diaspora has, thus, become an essential dimension of Black Digital Humanities. The Digital Black Atlantic (University of Minnesota Press, 2021), which Risam co-edited with Kelly Baker Josephs for the Debates in the Digital Humanities series, will be the first volume to articulate the scope and span of African diaspora digital humanities as a multidisciplinary, transnational assemblage of diverse scholarly practices spanning a range of disciplines (e.g., literary studies, history, library and information science, musicology) and methodologies (e.g., community archives, library collection development, textual analysis, network analysis).
African diaspora digital humanities, we contend, offers students opportunities to engage in active learning through participation in civically engaged scholarship. Such forms of authentic learning are “participatory, experimental, and carefully contextualized via real-world applications, situations, or problems” (Hancock et al. 2010, 38). They draw on scholarship that supports deep learning through the experiences of actively constructing knowledge (Downing et al. 2009; Ramsden 2003; Vanhorn et al. 2019). In the context of digital humanities, as Tanya Clement (2012), suggests, “Project-based learning in digital humanities demonstrates that when students learn how to study digital media, they are learning how to study knowledge production as it is represented in symbolic constructs that circulate within information systems that are themselves a form of knowledge production” (366). As Risam (2018) has argued, undertaking this work in the context of postcolonial and diaspora studies “empowers students to not only understand but also intervene in the gaps and silences that persist in the digital cultural record” (89–90). As projects like Amy E. Earhart and Toniesha L. Taylor’s White Violence, Black Resistance demonstrate, authentic learning through research-based projects in African diaspora studies “teach recovery, research, and digitization skills while expanding the digital canon” (Earhart and Taylor 2016, 252). Such projects allow undergraduate students to develop both digital and data literacy skills, which are often only implicitly taught in undergraduate courses, particularly in the humanities (Carlson et al. 2015; Battershill and Ross 2017; Anthonysamy 2020).
Approaches to the African diaspora that foreground working with data have shown particular promise as the technologies of recovery for which Gallon advocates. The Transatlantic Slave Trade Database, which aggregates data from slave ship records, was first conceived in the early 1990s by David Eltis, David Richardson, and Stephen Behrendt, researchers who were compiling data on enslavement and decided to join forces. Over the decades, the team and database expanded to include 36,000 voyages. The Transatlantic Slave Trade Database is now partnering with other projects on enslavement through Michigan State University’s Enslaved project, which is working to develop interoperable linked open data between these various databases. Projects like In the Same Boats, directed by Kaiama L. Glover and Alex Gil, with contributions from a team of scholars of the African diaspora (including Risam), demonstrate the value of a transnational, data-driven approach to more recent facets of African diasporic culture. The directors compiled data sets from their partners identifying the locations where Black writers and artists found themselves throughout the twentieth century and created data visualizations that show their intersections. While co-location of these figures at a given time does not necessarily mean they met, the project opens up new research questions about relationships and collaborations between them. The possibility of creating new avenues of transnational research is, perhaps, the most critical contribution of African diaspora digital humanities projects that focus on data.
But working with data in the context of the African diaspora is not an unambiguous proposition. Writing about the Transatlantic Slave Trade Database in her essay “Markup Bodies,” Jessica Marie Johnson argues, “Metrics in minutiae neither lanced historical trauma nor bridged the gap between the past itself and the search for redress” (2018, 62). In Dark Matters, Simone Brown notes that data has played a role in racialized surveillance from transatlantic slavery to the present and has been complicit with social control (2015, 16). COVID Black, a task force on Black health and data, directed by Kim Gallon, Faithe Day, and Nishani Frazier, along with a team, addresses racial disparities from the COVID-19 pandemic through data. Recognizing and addressing these issues is critical for African diaspora digital humanities projects that focus on data, particularly when working with undergraduate humanities students because of the twin challenges of students’ general lack of exposure to African diaspora studies and to data literacy in curricula.
Understanding Data through the Lens of Pan-Africanism
All of these issues came together in our project, Power Players of Pan-Africanism, which collects data on and develops data visualizations of attendees of Pan-Africanist gatherings from 1900 to 1959. Pan-Africanism, a social movement of great significance during the 20th century, fostered a sense of solidarity and political organization between people in Africa and African-descended people around the world. The timeframe encompasses the First Pan-African Conference in 1900, Pan-African Congresses held between 1919 and 1945, the Bandung Conference held in 1955, the Congresses of Black Writers and Artists in 1956 and 1959, the Afro-Asian Writers’ Conference in 1958, and assorted events during this time period that created space for people of Africa and its diaspora to meet and discuss their common political, social, and economic concerns. We chose to include events including Afro-Asian connections as well because they offered opportunities for Pan-Africanist connections in the broader context of Afro-Asian solidarity. Additionally, we ended in 1959 because 1960—widely known as the “Year of Africa”—saw the successes of decolonization movements in Africa and significantly changed the stakes of the conversation among Pan-Africanists.
While the idea for Power Players of Pan-Africanism emerged as a side project from Risam’s work on The Global Du Bois, a data visualization project that explores how computational data-driven research challenges, complicates, and assists with how we understand W.E.B. Du Bois’s role as a global actor in anticolonial struggles, and from her contribution of the Du Bois data set to Glover and Gil’s In the Same Boats, this project was undertaken as a collaboration between Risam and Mahoney, who together designed a plan for research, data collection and curation, and data modeling. We were joined in the Spring 2020 semester by Hibba Nassereddine, another student in the Digital Scholars Program, who collaborated with us on research for the data set, the iterative process of designing research questions based on the data, and prototyping of data visualizations.
The first challenge we encountered is that Pan-Africanism is largely unexamined within both high school and college curricula in the US. Despite its significance for understanding anti-colonial and anti-racist movements in the US and abroad, Pan-Africanism is a topic that goes largely unexplored in the classroom. However, its emphasis on global cooperation between Africa and its diaspora is poised to open up significant insights on the African diaspora, global history, political science, and literary studies, among others. The thriving network of intellectuals, artists, writers, and politicians who participated in Pan-Africanist movements reveals rich global connections and world travel that brought Black people of the US, Caribbean, Europe, and Africa into communication and collaboration during the first half of the 20th century. Thus, Mahoney, and later Nassereddine, first had to learn about an entirely new area of study in preparation for their participation in this project.
Data literacy is also a sorely missing part of curricula in high schools and colleges in the US. Therefore, both Mahoney and Nassereddine had to learn about working with data as well. We focused on the concept that data is situated, an idea that Jill Walker Rettberg has articulated (Rettberg 2020; Risam 2020). Data is not, as many think, objective and neutral but is a factor of how it is collected—who is collecting it, what terms are they using, what are their biases—and how it is represented—what choices are being made in data visualization and how does that affect how data is interpreted and received by audiences. We examined principles of data visualization, influenced by the work of Edward Tufte, Alberto Cairo, and Isabel Mereilles, to consider how data visualization risks misrepresenting or skewing data. Thus, to be prepared to undertake the project, Mahoney, and later Nassereddine, needed a firm grounding in data literacy and data ethics, which they had not received elsewhere in their education.
Recognizing the challenges of working with data in the context of the African diaspora, Risam and Mahoney set out to identify connections between attendees at Pan-Africanist events. By identifying conferences and other events that created space for Pan-Africanists to meet, we believed we could bring to life a data set that would reveal connections between figures in Pan-Africanist networks. Would network analysis reveal new key figures beyond names like Du Bois, George Padmore, Kwame Nkrumah, Marcus Garvey, Jomo Kenyatta, and Léopold Sédar Senghor?
Right away, we encountered another issue: the lack of readily available data sets for this work. The absence was not particularly surprising, as it reflects historical and ongoing marginalization of scholarship on the African diaspora more generally and Pan-Africanism specifically within academic knowledge production and archives. As Risam (2018) argues, the lack of preservation and digitization of material related to communities within the African diaspora and in the Global South is a major deterrent to undertaking digital humanities projects. Therefore, research to create a data set was a necessary precursor to data visualization.
This process turned out to be a lot more difficult than expected. We spent months digging into the history of Pan-Africanism, using monographs, journal articles, digital archives, theses and dissertations, historic Black newspapers, organization newsletters, and primary source documents from the events, such as published pamphlets listing attendees and photographs with captions to identify events where Pan-Africanism was an important focus and uncover names of delegates and other participants. Explicitly named “Pan-African” events (First Pan-African Conference, First Pan-African Congress, Second Pan-African Congress, etc.) were the easiest to identify. However, Pan-Africanist conferences went by many other names: writers’ conferences, peace conferences, and anti-colonial conferences. Furthermore, a single event often appears under multiple names, a factor of the relative lack of attention Pan-Africanism has received in academic discourse. In these cases, we labeled events by the names with which they most commonly appear in academic and archival sources. For example, we identify one event as the “All-African People’s Conference,” held in Accra, Ghana in December 1958 based on corroboration of sources, but this event is also referred to as the “Congress of African Peoples” (Adi and Sherwood 2003). Even more confusingly, Immanuel Geiss’s The Pan-African Movement (1974), arguably the first scholarly treatment of Pan-Africanism, refers to the All-African People’s Conference as the “Sixth Pan-African Congress,” while the Sixth Pan-African Congress typically refers to an event held in Dar es Salaam, Tanzania in 1974 in the lineage of earlier Pan-African Congresses but in a different mode given the acceleration of decolonization from 1960 on. Some events were also unnamed. In one such case, we learned that West-African activist, editor, and teacher, Garan Kouyauté held an event in Paris in 1934, and we internally referred to this as “Kouyauté’s Event.” While we kept running into Kouyauté’s name in other sources, we were unable to find substantially more information about that particular event. This became a common theme in our research, where individuals clearly played important roles in the Pan-African movement but do not commonly appear among the most cited figures in scholarship on Pan-Africanist thought. These omissions suggest that there is still much more research on Pan-Africanism that needs to be done, but their inclusion in our data set offers researchers new names of figures whose influence on Pan-Africanism should be pursued.
Despite this challenge, the research process often delivered moments of validation, when the simple act of locating multiple obscure sources confirming an event made us grateful that we could prove that it happened. Therefore, the work of creating the data set was itself a scholarly activity, using both primary and secondary sources to validate the existence of lesser-known Pan-Africanist gatherings that deserve better recognition. For example, in The Pan-African Movement (1974), Geiss introduces an event called, “The Negro in the World Today.” Harold Moody, a Jamaican-born physician residing in London, hosted said event in July 1934 to coincide with a visit from a Gold Coast delegation, including prince and politician Nana Ofori Atta. Geiss explains, “One of the motives given for convening was the racial discrimination which faced coloured workers and students in Britain” (1974, 357). This event, among others, led to the Fifth Pan-African Congress in October 1945 in Manchester, England. However, finding any details of who attended “The Negro in the World Today” proved fruitless, and we almost started to question if this event was significant enough to be included in the data set. A bright moment in our research occurred when we found the event named in a newspaper article titled, “Africans Hold Important Three-Day Conference in London” in the July 21, 1934 issue of The Pittsburgh Courier (ANP 1934, 2). Confirming the existence of this event was celebratory, and these exuberant moments made many excruciating hours of research where we turned up nothing worth it. All told, we identified close to seventy events within our timeframe that fit our criteria of explicitly creating space for Pan-African connections among Black participants from around the world.
More obstacles appeared as we worked to identify the names of delegates and other participants in these events. In some cases, sources only identify the names of organizations being represented and did not include the names of people from the organization who were in attendance. Often, we had much more success identifying the numbers of delegates and attendees at events than locating their names. Knowing the numbers, however, gave us a sense of the percentage of attendee names that we had confirmed. For example, we know that there were over 200 delegates and 5,000 participants at the Fourth Pan-African Congress, held in New York in 1927, but we have only successfully identified twenty-six of those names. In our most successful case, the Conference on Africa, held in New York in 1944, we identified names of all 112 delegates, as well as additional participants and observers.
Among the many names that we added to our data set, we encountered further discrepancies we had to address. Some of the same participants were listed under different names in multiple sources, requiring additional research to verify. In some cases, this was a matter of typos within the sources. For example, a participant named “William Fonaine” attended the First International Conference of Negro Writers and Artists, and a participant named “W. F. Fontaine” attended the Second International Conference of Negro Writers and Artists. We were able to confirm that William F. Fontaine attended both events. In other cases, delegates had changed their names, which was not unusual at the time. In some instances, people changed their names to embrace their African roots and resist the imposition of colonial languages on their identities. T. Ras Makonnen was born George Thomas N. Griffiths in 1900 but changed his name in 1935. Kwame Nkrumah, born Francis Nwia Kofi Nkrumah in 1909, changed his name to Kwame Nkrumah in 1945 (and later became the first Prime Minister and then first President of Ghana). In other cases, differences in non-Anglophone names reflected divergent transliteration practices. We chose to include delegates’ country or colony of origin as well, which introduced a further level of inconsistency. Of course, we encountered changes in names reflecting transitions from colony to independent nation, such as Gold Coast to Ghana. But there were more puzzling inconsistencies as well. In many cases this reflected the mobility of participants in Pan-Africanism, their shifting national allegiances, and/or their affiliation with multiple locales. For others, however, it reflects inconsistencies in archival materials. In perhaps the oddest case, we found “Miguel Francis Delanang” from Ethiopia attending the Bandung Conference and a “Miguel Francis Delanang” from Ghana at the same conference. Based on our research, this is the same person. While we have done our best to identify as many discrepancies as we could, we fully expect that others exist that we have not caught because they are less obvious, such as aliases or pseudonyms that we have not yet connected to another name. Therefore, we view our data set not as a static and finished object but a living, collaborative document for other researchers who want to contribute to it.
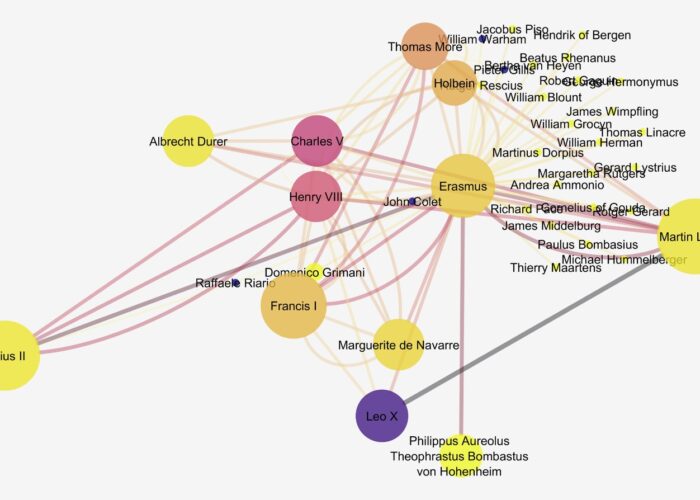
Although we could easily spend years continuing our research, we decided that we had a substantial enough amount of data for a subset of twenty-one events that we could use to begin prototyping our data visualizations. When we began the project, we were curious about the networks among the participants. Would a network show significant connections among participants? How dense would these networks be? Which figures would be the hubs in the network? Would they be the usual suspects or might new voices emerge? To explore these questions, we created a force-directed graph—and the results were virtually meaningless. There was little density in the network and few connections among attendees. Light clustering in the network appeared around W.E.B. Du Bois, widely known as the father of Pan-Africanism, which was hardly surprising.
These disappointing results prompted several teachable moments about data and research design. We looked closely at our data set to understand why the network visualization seemed little more than noise. While we had expected to find participants attending more than one event, our twenty-one events gave us over one thousand names with the majority only attending one event. Logically, it was unsurprising that better-known figures like Du Bois attended more events because they had access to the means to do so. Also, since our events spanned six decades punctuated by major events like World Wars I and II, the rise of the Soviet Union, and the beginning of decolonization, the power players in the movement changed as their investment in Pan-Africanism waxed and waned over time. We also know, based on the information we had found about the total numbers of participants, that some of our data sets were incomplete—and may always be incomplete. Without accounting for the situatedness of the data we had curated, the results simply did not make sense.
We also recognized that our initial hypothesis about the existence of a network with well-defined connections was an erroneous assumption. Engagement of delegates with an event did not necessarily imply extended participation in the global dimensions of a movement. This realization led us to reconsider how we imagine what “participating” in a social movement means. In a conversation about these challenges, digital humanist Quinn Dombrowski suggested that perhaps what is most meaningful lies not in the network but in the brokenness of the network—in what a network visualization cannot represent. There may, for example, be forms of participation that cannot be captured within the bounds of face-to-face gatherings. These might be captured, instead, through correspondence between those engaged in Pan-Africanism. There might also be local effects of an individual’s attendance at an event that similarly would not manifest in a network visualization of participants. Rather than offer a clear picture of Pan-Africanism, our data set and meaningless network visualization opened up a new set of questions about the role of digital humanities in understanding Pan-Africanism.
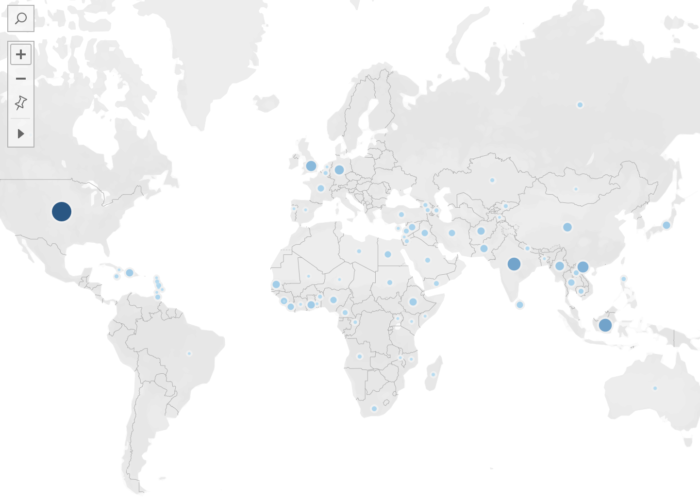
This misstep was also an opportunity to explore the iterative nature of project design with students. Digital humanists, after all, are not unaccustomed to encountering failure and pivoting with research questions and methods to see what these methods make possible (Dombrowski 2019; Graham 2019). Engaging with iterative project design and negotiating the inevitable errors offers undergraduate students the opportunity to develop both creativity and problem solving skills (Pierrakos et al. 2010; Shernoff et al. 2011; Wood and Bilsborow 2013). We began to ask new questions about our data set and continued developing prototypes to see if they offered more meaningful insight on the data. One question that emerged was how to visualize the data in a way that would make the events and delegate information more easily navigable than reading a spreadsheet. We experimented with a sunburst data visualization, which shows hierarchical relationships between data. The top level of the hierarchy focused on decades, then years, then events, and finally participants. The sunburst visualization allowed us to organize the data and provide easy access to a complex data set, while also representing the data proportionally (which decades and years included the most events and which events included the largest numbers of delegates). Another question we considered was how our data might speak to the reach of Pan-Africanism both geographically and temporally. We created two maps to examine this question. The first, a static map, simply dropped pins at the locations of the nearly seventy events we had identified, revealing a broad geographical scope for Pan-Africanist gatherings—in the US, the Caribbean, Europe, Africa, and Asia. A second map, focusing on the twenty-one events for which we had identified a significant number of participants, mapped the attendees’ colonies and countries of origin. This dynamic heat map, animated to aggregate participant data over time, demonstrated the significant geographic scope of Pan-Africanism and its growth and spread over the first sixty years of the 20th century. Critically, we understood these visualizations as representations of particular elements of our data set, each shedding light on different details within the data but none showing the entire picture. While this is a feature of digital humanities scholarship that engages with data more generally—data visualizations are representations that slice and sample data sets, showing particular aspects of the data—it is a critical way of understanding data-driven approaches to African diaspora digital humanities.
Teaching (and Learning) Data Literacy with African Diaspora Digital Humanities
Despite the challenges of this work, we came away from the experience with key insights for both scholarship of the African diaspora and pedagogy. Risam was reminded that when working in the context of a subject that has been marginalized in the broader landscape of scholarly knowledge production, we are inherently limited by what archives have preserved and what scholarship has covered. Our research is encumbered by what Risam (2018) has described as the omissions of the cultural record, and as much as we can undertake the important work—like curating data sets—to avoid reproducing and amplifying these gaps, we inevitably must contend with fragments of information and the larger question of what data can and cannot reveal about the African diaspora. Although this knowledge ultimately proved frustrating, it was profound for Mahoney and Nassereddine in their first foray into working with data. Risam also found the experience an instructive lesson in how to teach humanities students to engage with data when we miss the mark—e.g. when our presumptions about the network failed to pan out. While scientific methods in STEM prompt students to contemplate and negotiate failure, this is not typically foregrounded in humanities methodologies (Henry et al. 2019; Melo et al. 2019; Croxall and Warnick 2020). However, this project offered Risam the opportunity to encourage students to move away from assumptions and be open to the new insights that emerge from a challenge. As Mahoney and Nassereddine are both students pursuing their teaching licenses in English, Risam used this experience as an opportunity to model reflective practice for the heartbreaks we encounter in both digital humanities research and in teaching—sometimes one’s brilliant idea does not prove to be so in execution, and the appropriate response is not to shut down and yield to failure but to pivot—ask questions, reassess, and re-plan.
From this experience, Mahoney had the opportunity to delve deeply into archival research and scholarship on the African diaspora for the first time. She was also surprised to learn that many high school teachers and professors with whom she discussed her work had not heard of Pan-Africanism, reflecting the lack of coverage of this powerful movement within high school and college curricula. Conversely, projects like ours are examples of how we can engage students in addressing these gaps in both curriculum and the cultural record (Risam 2018; Hill and Dorsey 2019; Thompson and McIlnay 2019; Dallacqua and Sheahan 2020; Davila and Epstein 2020). This project also led Mahoney to realize that often we are left with more questions than answers. For example, what breakthroughs or achievements for the African diaspora did Pan-Africanist gatherings create? How were these participants, who faced travel or visa restrictions, funding their travels for these events? Mahoney also discovered the moments of serendipity, joy, and surprise that are part of the research experience, in the way it opens up a virtually limitless garden of forking paths to explore. She was particularly excited to uncover the significance of women to Pan-Africanism. The Fourth-Pan African Congress in New York in 1927, for example, was organized primarily by women. Although women’s names are not counted among the key figures of Pan-Africanism, through the curation of our data set, Mahoney identified that Amy Ashwood Garvey, the first wife of well-known Pan-Africanist Marcus Garvey, arguably played a more significant role in Pan-Africanism than her husband. Aside from one out-of-print biography, Lionel M. Yard’s Biography of Amy Ashwood Garvey, 1897–1969, there is little research focused on Ashwood Garvey, but Mahoney was able to reconstruct her role. Ashwood Garvey used her father’s credit to help Garvey found the Universal Negro Improvement Association in Jamaica, and she worked with Garvey in the US, where they were married and divorced within two years. After their separation, Ashwood Garvey committed herself to Pan-Africanism, co-founding the Nigerian Progress Union and the International African Friends of Abyssinia (later the International African Service Bureau). Additionally, she was a respected speaker at Pan-Africanist and other political events throughout Europe, the Caribbean, the United States, and Africa. After organizing the Fifth Pan-African Congress in Manchester, England in 1945, Ashwood Garvey spent several years in Africa speaking to women and children and raising money for schools, lecturing in Nigeria, residing for two years as a guest of the Asantehene in Kumasi, Ghana, and adopting two daughters in Monrovia, Liberia. Later in her life, she opened the Afro-Woman Service Bureau in London. Mahoney began to recognize the questions that emerged as a factor of the relative lack of scholarly attention that Pan-Africanism has received in spite of its significance, which is a reflection of the biases within the cultural record—and in curriculum—that favor knowledge production on canonical histories, figures, and movements of the Global North over the stories and voices of the Global South (Akua 2019; Lehner and Ziegler 2019; Span and Sanya 2019; Caldwell and Chávez 2020). This experience also led Mahoney to recognize the importance of incorporating the voices of Black writers and artists engaged in Pan-Africanism into her classroom as a high school teacher.
From her crash course in data literacy while working on the project, Mahoney also realized that digital humanities must be included in the high school English Language Arts classroom. Contextualizing her experiences in her prior coursework on English teaching methods and technology teaching methods, Mahoney came to understand digital humanities as a way of teaching data literacy to her own students. In Massachusetts, where Mahoney will be teaching, high school teachers are beholden to the Massachusetts Curriculum Frameworks, which are based on Common Core Standards. In 2016, Massachusetts released Digital Literacy Standards, but there has been no incentive, accountability, or professional development provided to support their implementation. African diaspora digital humanities, in particular, Mahoney recognized, facilitates students’ digital literacy while furthering the essential goal of expanding the canon in the classroom to ensure inclusive representation for all students. Focusing on the two together allows teachers to move past perceived barriers—such as the cost of adding new books to curriculum or lack of interest from colleagues—to work towards justice and equity through students’ engagement with data. In the context of working with informational texts in the Common Core Standards, data literacy encourages students to understand the ethics of data and data visualizations—How was data collected? Who collected the data? What questions were asked? What terminology was used to ask the questions and how might that have informed the response? What is the difference between quantitative and qualitative data? What implicit messages appear in data visualizations? What stories can they tell and what are their limits?
We, therefore, propose that African diaspora digital humanities has an essential role to play in pedagogy, particularly at the high school level. Reading and analyzing data sets and data visualization is a cross-disciplinary skill that needs to be incorporated across the curriculum, and English Language Arts teachers have a responsibility to ensure that students are prepared to understand data, as a cornerstone of literacy. Teaching data literacy holds the possibility of appealing to students who might struggle with or be less interested in literature, allowing teachers to leverage their engagement with data sets and data visualization into deeper connections to the practices of reading and analyzing texts, while building their knowledge of the social value of data literacy (Kjelvik and Schultheis 2019; Špiranec et al. 2019; Bergdahl et al. 2020). Furthermore, it acquaints students with the iterative nature of research and interpretation, while building their capacity to recognize failure and to redirect their efforts towards new avenues of inquiry that may be more fruitful. This is not a matter of “grit”—the troubling emphasis on underserved students’ attitudes towards perseverance rather than on the structural oppressions that impede learning (Barile 2014; Duckworth 2016; Stitzlein 2018)—but strengthening critical thinking skills, particularly when working with English language learners (Parris and Estrada 2019; Smith 2019; Yang et al. 2020). Working with data of the African diaspora also contributes to greater diversity within curricula, while encouraging students to recognize the power dynamics at play in whose voices and experiences are preserved in the artifacts that form our cultural record. Ensuring that students have the opportunity to learn about the Black writers and artists who were the power players of Pan-Africanism in the context of data literacy offers teachers the possibility of promoting equity in the classroom and developing students’ ability to use their knowledge to interpret data through an ethical lens beyond the classroom.
Bibliography
Akua, Chike. 2019. “Standards of Afrocentric Education for School Leaders and Teachers.” Journal of Black Studies 51, no. 2 (December): 107–27. https://doi.org/10.1177/0021934719893572.
Associated Negro Press. 1934. “Africans Hold Important Three-Day Conference in London.” The Pittsburgh Courier, July 21, 1934.
Adi, Hakim, and Marika Sherwood. 2003. Pan-African History: Political Figures From Africa and the Diaspora Since 1787. London: Routledge.
Anthonysamy, Lilian. 2020. “Digital Literacy Deficiencies in Digital Learning Among Undergraduates” In Understanding Digital Industry, edited by Siska Noviaristanti, Hasni Mohd Hanafi, and Donny Trihanondo, 133–36. London: Routledge.
Barile, Nancy. 2014. “Is “Getting Gritty” the Answer?: Can Grit Solve All Your Students’ Problems? This Urban High School Teacher Shares Her Experiences.” Educational Horizons 93, no. 2 (December): 8–9. https://doi.org/10.1177/0013175X14561418.
Battershill, Claire and Shawna Ross. 2017. Using Digital Humanities in the Classroom: A Practical Introduction for Teachers, Lecturers, and Students. London: Bloomsbury Academic.
Bergdahl, Nina, Jalal Nouri, and Uno Fors. 2019. “Disengagement, Engagement and Digital Skills in Technology-enhanced Learning.” Education and Information Technologies 25: 957–983. https://doi.org/10.1007/s10639-019-09998-w.
Brown, Simone. 2015. Dark Matters: On the Surveillance of Blackness. Durham, NC: Duke University Press.
Cairo, Alberto. 2019. How Charts Lie: Getting Smarter about Visual Information. NY: Norton.
Caldwell, Kia Lilly, and Emily Susanna Chávez. 2020. Engaging the African Diaspora in K–12 Education. New York: Peter Lang Publishing Group.
Carlson, Jake, Megan Sapp Nelson, Lisa R. Johnston, and Amy Koshoffer. 2015. “Developing Data Literacy Programs: Working with Faculty, Graduate Students and Undergraduates.” Bulletin of the Association for Information Science and Technology 41, no. 6 (August/September): 14–17.
Clement, Tanya. 2012. “Multiliteracies in the Undergraduate Digital Humanities Curriculum: Skills, Principles, and Habits of Mind.” In Digital Humanities Pedagogy: Practices, Principles, and Politics, edited by Brett D. Hirsch, 365–88. Cambridge: Open Book Publishers.
Croxall, Brian, and Quinn Warnick. 2020. “Failure.” In Digital Pedagogy in the Humanities: Concepts, Models, and Experiments, edited by Rebecca Frost Davis, Matthew K. Gold, Katherine D. Harris, and Jentery Sayers. https://digitalpedagogy.hcommons.org/keyword/Failure.
Dallacqua, Ashley K., and Annmarie Sheahan. 2020. “Making Space: Complicating a Canonical Text Through Critical, Multimodal Work in a Secondary Language Arts Classroom.” Journal of Adolescent & Adult Literacy 64, no. 1 (July/August): 67–77. https://doi.org/10.1002/jaal.1063.
Davila, Denise, and Elouise Epstein. 2020. “Contemporary and Pre–World War II Queer Communities: An Interdisciplinary Inquiry Via Multimodal Texts.” English Journal 110, no. 1 (September): 72–79.
Dombrowski, Quinn. 2019. “Towards a Taxonomy of Failure.” http://quinndombrowski.com/?q=blog/2019/01/30/towards-taxonomy-failure.
Downing, Kevin, Theresa Kwong, Sui-Wah Chan, Tsz-Fung Lam, and Woo-Kyung Downing. 2009. “Problem-based Learning and the Development of Metacognition.” Higher Education 57: 609–621.
Duckworth, Angela. 2016. Grit: The Power of Passion and Perseverance. New York: Scribner.
Earhart, Amy E. and Toniesha L. Taylor. 2016. “Pedagogies of Race: Digital Humanities in the Age of Ferguson.” In Debates in the Digital Humanities 2016, edited by Matthew K. Gold and Lauren F. Klein, 251–264. Minneapolis: University of Minnesota Press.
Eltis, David, et al. 2020. The Transatlantic Slave Trade Database. https://www.slavevoyages.org.
Gallon, Kim. 2016. “Making the Case for Black Digital Humanities.” In Debates in the Digital Humanities 2016, edited by Matthew K. Gold and Lauren F. Klein, 43–49. Minneapolis: University of Minnesota Press.
Gallon, Kim et al. 2020. COVID Black. https://www.cla.purdue.edu/academic/sis/p/african-american/covid-black/team.html.
Geiss, Imanuel. 1974. The Pan-African Movement. New York: Africana Publishing Company.
Glover, Kaiama L. and Alex Gil. 2020. In the Same Boats. https://sameboats.org.
Graham, Shawn. 2019. Failing Gloriously and Other Essays. Grand Forks, ND: The Digital Press.
Hancock, Thomas, Stella Smith, Candace Timpte, and Jennifer Wunder. 2010. “PALs: Fostering Student Engagement and Interactive Learning.” Journal of Higher Education Outreach and Engagement 14, no. 4. https://openjournals.libs.uga.edu/jheoe/article/view/798/798.
Henry, Meredith A., Shayla Shorter, Louise Charkoudian, Jennifer M. Heemstra, and Lisa A. Corwin. 2019. “FAIL Is Not a Four-Letter Word: A Theoretical Framework for Exploring Undergraduate Students’ Approaches to Academic Challenge and Responses to Failure in STEM Learning Environments.” CBE—Life Sciences Education 18, no. 1 (Spring): 1–17. https://doi.org/10.1187/cbe.18-06-0108.
Hill, Craig, and Jennifer Dorsey. 2020. “Expanding the Map of the Literary Canon Through Multimodal Texts.” In Handbook of the Changing World Language Map, edited by Stanley D. Brunn and Roland Kehrein, 77–89. Cham, Switzerland: Springer.
Johnson, Jessica Marie. 2018. “Markup Bodies: Black [Life] Studies and Slavery [Death] Studies at the Digital Crossroads.” Social Text 36, no. 4 (2018): 57–79. https://doi.org/10.1215/01642472-7145658.
Johnston, Brenda, Peter Ford, Rosamond Mitchell, and Florence Myles. 2011. Developing Student Criticality in Higher Education: Undergraduate Learning in the Arts and Social Sciences. London: Bloomsbury Publishing.
Kjelvik, Melissa K., and Elizabeth H. Schultheis. 2019. “Getting Messy with Authentic Data: Exploring the Potential of Using Data from Scientific Research to Support Student Data Literacy.” CBE—Life Sciences Education 18, no. 2 (Summer): 1–18. https://doi.org/10.1187/cbe.18-02-0023.
Lehner, Edward and John R. Ziegler. 2019. “Re-Conceptualizing Race in New York City’s High School Social Studies Classrooms.” In Handbook of Research on Social Inequality and Education, edited by Sherrie Wisdom, Lynda Leavitt, and Cynthia Bice, 24–45. Hershey, Pennsylvania: IGI Global.
Meirelles, Isabel. 2013. Design for Information. Beverly, Massachusetts: Rockport Press.
Melo, Marijel, Elizabeth Bentely, Ken S. McAllister, and José Cortez. 2019. “Pedagogy of Productive Failure: Navigating the Challenges of Integrating VR into the Classroom.” Journal of Virtual Worlds Research 12, no. 1 (January): 1–20. https://doi.org/10.4101/jvwr.v12i1.7318.
Noble, Safiya Umoja. 2019. “Toward a Critical Black Digital Humanities.” In Debates in the Digital Humanities, edited by Matthew K. Gold and Lauren F. Klein, 25–35. Minneapolis: University of Minnesota Press.
Pangrazio, Luci, and Julian Sefton-Green. 2020. “The Social Utility of ‘Data Literacy.’” Learning, Media, and Technology 45, no. 2 (June): 208–20. https://doi.org/10.1080/17439884.2020.1707223.
Parham, Marissa. 2019. “Sample | Signal | Strobe: Haunting, Social Media, and Black Digitality.” In Debates in the Digital Humanities, edited by Matthew K. Gold and Lauren F. Klein, 101–122. Minneapolis: University of Minnesota Press.
Parris, Heather, and Lisa M. Estrada. 2019. “Digital Age Teaching for English Learners.” In The Handbook of TESOL in K‐12, edited by Luciana C. de Oliveria, 149–62. Hoboken, New Jersey: Wiley-Blackwell.
Pierrakos, Olga, Anna Zilberberg, and Robin Anderson. 2010. “Understanding Undergraduate Research Experiences through the Lens of Problem-based Learning: Implications for Curriculum Translation.” Interdisciplinary Journal of Problem-Based Learning 4, no. 2 (September): 35–62. https://doi.org/10.7771/1541–5015.1103.
Ramsden, Paul. 2003. Learning to Teach in Higher Education. New York: Routledge.
Rettberg, Jill Walker. 2020. “Situated Data Analysis: A New Method for Analysing Encoded Power Relationships in Social Media Platforms and Apps.” Humanities and Social Sciences Communications 7, no. 5 (2020). https://doi.org/10.1057/s41599-020-0495-3.
Risam, Roopika. 2020. “‘It’s Data, Not Reality’: On Situated Data with Jill Walker Rettberg.” Nightingale, June 29, 2020. https://medium.com/nightingale/its-data-not-reality-on-situated-data-with-jill-walker-rettberg-d27c71b0b451.
Risam, Roopika. 2018. New Digital Worlds: Postcolonial Digital Humanities in Theory, Praxis, and Pedagogy. Evanston, Illinois: Northwestern University Press.
Shernoff, Elisa S., Ane M. Maríñez-Lora, Stacy L. Frazier, Lara J. Jakobsons, Marc S. Atkins, and Deborah Bonner. 2011. “Teachers Supporting Teachers in Urban Schools: What Iterative Research Designs Can Teach Us.” School Psychology Review 40, no. 4 (December): 465–85. https://doi.org/10.1080/02796015.2011.12087525.
Smith, Blaine E. 2019. “Mediational Modalities: Adolescents Collaboratively Interpreting Literature through Digital Multimodal Composing.” Research in the Teaching of English 53, no. 3 (February): 197–222. https://search.proquest.com/docview/2196370157?pq-origsite=gscholar&fromopenview=true.
Span, Christopher M., and Brenda N. Sanya. 2019. “Education and the African Diaspora.” In The Oxford Handbook of History Education, edited by John L. Rury and Eileen H. Tamura, 399–412. New York: Oxford University Press.
Špiranec, Sonja, Denis Kos, and Michael George. 2019. “Searching for Critical Dimensions in Data Literacy.” In Proceedings of CoLIS, the Tenth International Conference on Conceptions of Library and Information Science, Ljubljana, Slovenia, June 16–19, 2019. Information Research 24, no. 4 (December). http://informationr.net/ir/24-4/colis/colis1922.html.
Stitzlein, Sarah M. 2018. “Teaching for Hope in the Era of Grit.” Teachers College Record 120, no. 3 (March): 1–28. http://www.tcrecord.org/Content.asp?ContentId=22085.
Thompson, Riki, and Matthew McIlnay. 2019. “Nobody Wants to Read Anymore! Using a Multimodal Approach to Make Literature Engaging.” Journal of English Language and Literature 7, no. 1 (January): 21–40.
https://www.researchgate.net/publication/341312737.
Tufte, Edwards. 2001. The Visual Display of Quantitative Information, 2nd edition. Cheshire, Connecticut: Graphics Press.
Vanhorn, Shannon, Susan M. Ward, Kimberly M. Weismann, Heather Crandall, Jonna Reule, et al. 2019. “Exploring Active Learning Theories, Practices, and Contexts.” Communication Research Trends 38, no. 3 (January): 5–25.
https://search.proquest.com/docview/2308823162?fromopenview=true&pq-origsite=gscholar.
Wood, Denise, and Carolyn Bilsborow. 2015. “‘I am not a Person with a Creative Mind’: Facilitating Creativity in the Undergraduate Curriculum Through a Design-Based Research Approach.” In Leading Issues in e-Learning Research MOOCs and Flip: What’s Really Changing?, edited by Mélanie Ciussi, 79–107. United Kingdom: Academic Conferences and Publishing Limited.
Yang, Ya-Ting Carolyn, Yi-Chien Chen, and Hsui-Ting Hun. 2020. “Digital Storytelling as an Interdisciplinary Project to Improve Students’ English Speaking and Creative Thinking.” Computer Assisted Language Learning. https://doi.org/10.1080/09588221.2020.1750431.