While not a perfect analogy, this scenario does begin to illustrate one of the key challenges we’ve faced working on the shift of our publishing platform to Manifold: the procedure by which we move our old, archived content to the new system. It’s not a big deal if you’re only moving one or two pieces of content—you can just copy and paste things. JITP has over three hundred articles, though, so we need a plan for dealing with all these articles, staged in layout by different teams at different times, programmatically. Technical platforms are generally quite opinionated about how they organize their data, and each one makes particular decisions that might not translate well to another setup. If you’re lucky, your old platform will have a mechanism by which you export your data into a format readable by the new one. But even in the best of circumstances the process rarely works seamlessly and can require dozens or hundreds of hours of work to finish the process and make everything uniform across the archive. It’s something akin to saying, “Before I even begin to set this table, I need to reorganize this kitchen to be how I’m used to. Oh, and also I need to move my own silverware in to do this properly. Surprise—we’re now roommates.”
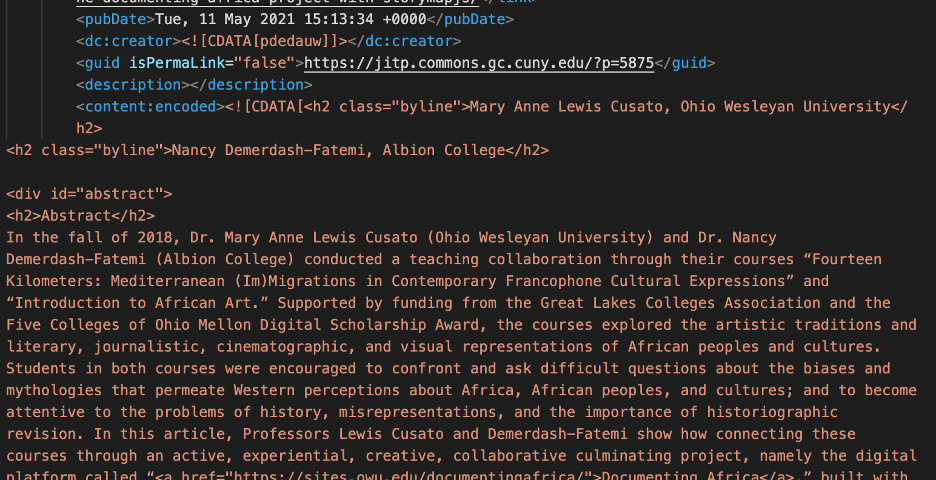
With every migration, it’s important to know where you’re starting from and where you are hoping to end up. JITP has historically been hosted on WordPress, a popular blogging platform. Each individual post is more than just the text of an article; it also contains an author, a date, a featured image, comments, and more. The complicated bit, then, is how all this metadata gets packaged together with the post to be transferred. WordPress has an export tool that provides a dump of your data in a format called XML, a standard markup language similar to HTML, the backbone of the web. We started with this export. Here’s an example article from Issue 19, and its exported code (Figure 1), to show what the XML export looks like. Note the combination of metadata about the text with the content itself as well as the embedded HTML, such as hyperlinks and structural information.

So, having successfully gotten everything out of WordPress, we faced our next hurdle: Manifold cannot take in XML directly. We needed to look at options to convert what we had to what we needed. First, Migration Lead Kelly Hammond used a freely available script to convert our XML to Markdown, a more lightweight language that Manifold could actually ingest. Here is the same article in Markdown for comparison:

The Markdown ingestion worked, and we were able to get things directly onto Manifold. As mentioned, Markdown is more lightweight as a format, trading off the much more nuanced and complicated options that you get with HTML for a format that highlights with more clarity the features you are most likely to need when writing articles for the web. The result is quicker to write and more legible to the naked eye, both of which are probably legible from the screenshots above (Figures 1 and 2). As with any trade-off, some of the features we gave up nevertheless proved themselves important enough to pose a problem, though in ways that might not be immediately legible. Take these two versions of the same byline (Figure 3), the first in HTML and the second in Markdown:

They both represent the byline as a second-level header, but only the HTML version gives it a CSS class of “byline,” which WordPress would use to flag authors’ names for consistent styling across all issues. This type of information gets lost in the transition to Markdown, and so we would find that we needed to find some way to maintain a relatively simple, ingestible format that would nonetheless retain some key CSS information, so that similar components of articles would be styled the same way across the newly migrated archive. The other limitation of the Markdown conversion script was that it was created by someone else. That’s great in one way—no need to reinvent the wheel. But it also meant it was very hard to change for our own purposes.
Ultimately, I decided to develop our own solution by writing a script in Python to scrape the JITP site directly. If you’re not familiar, web scraping is essentially the equivalent of asking a computer to copy and paste web information at scale. Because the script would be targeting the live site, it meant that we got all the information visible to the user. I won’t go into all details of the script itself, but you can view it at this gist link or below if you are interested.
https://gist.github.com/walshbr/ef1ebfb4550570047cec5d5ecf45ebd2.js
Because we wrote the script ourselves, it meant that we had a high degree of control over what the output looked like over and above just getting access to the data we needed. This meant that, for example, as we advanced in the conversations about the migration, we had an easy way to make adjustments. One example of this: a particular CSS class category had had a few names for the same function over the various years of the journal’s existence, and so even with some nudging our styling would look inconsistent. Rather than having someone manually go in and edit hundreds of files, we could take care of that with a single line of code, replacing all of the variations with one CSS class name. We could also make surgical interventions to remove particular elements that we didn’t want to keep in the new platform.
This process took a lot of time and energy, but it’s work that has hopefully made the migration more manageable in the long term. It’s given us an opportunity to look back at content that hasn’t been touched in years and think about how best to sustain it over time. Hopefully, the result will renew interest in all of the fantastic work authors and editorial collective members put into pieces in the back catalog of the journal, reanimating debates from new perspectives. Likewise, we hope this short glimpse into our process of reorganizing our own drawers might spark some ideas about your own digital projects, making it a smidge easier to cook with guests—as we so often do.

'Troublescraping: Migrating JITP’s Archive to Manifold' has 2 comments
March 22, 2024 @ 12:37 am Lowes Survey
Lowes allows all the residents of the United States to take part in the customer satisfaction survey. It welcomes all the survey participants to give honest feedback about their last visit. Thus, by providing the feedback, all the customers enter into the sweepstakes directly for a $500 check. As it is a monthly contest, five lucky winners will be selected as the winners. So, take the Lowes survey here. Thank you for providing the feedback; your responses are valuable – regards.
September 11, 2022 @ 5:35 am تصليح افران غاز
If you have a gas stove or oven, it is important to know how to keep it in good condition. This means figuring out how he or she successfully fixed the problem. Gas appliances can be dangerous properly, so safety and knowledge are key. In this blog post